スキーマの設計
これは、PostgreSQLからClickHouseへの移行ガイドのパート2です。このコンテンツは入門的なものであり、ClickHouseのベストプラクティスに従った初期の機能的なシステムを展開するのに役立ちます。複雑なトピックは避け、完全に最適化されたスキーマにはなりませんが、ユーザーが本番システムを構築し、その学習の基礎を築くのに役立つ堅実な基盤を提供します。
Stack Overflowデータセットには、関連する複数のテーブルが含まれています。移行では、主要なテーブルを最初に移行することをお勧めします。これは必ずしも最大のテーブルではなく、むしろ最も多くの分析クエリを受けると期待されるテーブルです。これにより、特にOLTP中心のバックグラウンドを持つ場合、ClickHouseの主要な概念に慣れることができます。このテーブルは、ClickHouseの機能を最大限に活用し、最適なパフォーマンスを得るために、追加のテーブルが追加されるたびにリモデリングを必要とするかもしれません。このモデリングプロセスについては、データモデリングのドキュメントで探ります。
初期スキーマの設定
この原則に従い、主要なpostsテーブルに焦点を当てます。Postgresスキーマは以下のように示されています:
CREATE TABLE posts (
Id int,
PostTypeId int,
AcceptedAnswerId text,
CreationDate timestamp,
Score int,
ViewCount int,
Body text,
OwnerUserId int,
OwnerDisplayName text,
LastEditorUserId text,
LastEditorDisplayName text,
LastEditDate timestamp,
LastActivityDate timestamp,
Title text,
Tags text,
AnswerCount int,
CommentCount int,
FavoriteCount int,
ContentLicense text,
ParentId text,
CommunityOwnedDate timestamp,
ClosedDate timestamp,
PRIMARY KEY (Id),
FOREIGN KEY (OwnerUserId) REFERENCES users(Id)
)
上記の各カラムに対応するTypeを確立するには、Postgresテーブル関数と共にDESCRIBEコマンドを使用できます。次のコマンドをPostgresインスタンスに合わせて変更してください:
DESCRIBE TABLE postgresql('<host>:<port>', 'postgres', 'posts', '<username>', '<password>')
SETTINGS describe_compact_output = 1
┌─name──────────────────┬─type────────────────────┐
│ id │ Int32 │
│ posttypeid │ Nullable(Int32) │
│ acceptedanswerid │ Nullable(String) │
│ creationdate │ Nullable(DateTime64(6)) │
│ score │ Nullable(Int32) │
│ viewcount │ Nullable(Int32) │
│ body │ Nullable(String) │
│ owneruserid │ Nullable(Int32) │
│ ownerdisplayname │ Nullable(String) │
│ lasteditoruserid │ Nullable(String) │
│ lasteditordisplayname │ Nullable(String) │
│ lasteditdate │ Nullable(DateTime64(6)) │
│ lastactivitydate │ Nullable(DateTime64(6)) │
│ title │ Nullable(String) │
│ tags │ Nullable(String) │
│ answercount │ Nullable(Int32) │
│ commentcount │ Nullable(Int32) │
│ favoritecount │ Nullable(Int32) │
│ contentlicense │ Nullable(String) │
│ parentid │ Nullable(String) │
│ communityowneddate │ Nullable(DateTime64(6)) │
│ closeddate │ Nullable(DateTime64(6)) │
└───────────────────────┴─────────────────────────┘
22 rows in set. Elapsed: 0.478 sec.
これにより、初期の非最適化スキーマが提供されます。
NOT NULL 制約がなければ、PostgresのカラムにはNull値が含まれる可能性があります。行の値を調べずに、ClickHouseはこれらを同等のNullable型にマッピングします。Postgresでは、主キーはNullでないことが要求事項です。
これらの型を使用して、ClickHouseでテーブルを作成するには、CREATE AS EMPTY SELECTコマンドをシンプルに使用できます。
CREATE TABLE posts
ENGINE = MergeTree
ORDER BY () EMPTY AS
SELECT * FROM postgresql('<host>:<port>', 'postgres', 'posts', '<username>', '<password>')
このアプローチは、他のフォーマットでs3からデータをロードするためにも使用できます。同等の例として、このデータをParquetフォーマットからロードする例を参照してください。
初期ロード
作成されたテーブルを使用して、PostgresからClickHouseに行を挿入します。Postgresテーブル関数を使用します。
INSERT INTO posts SELECT *
FROM postgresql('<host>:<port>', 'postgres', 'posts', '<username>', '<password>')
0 rows in set. Elapsed: 1136.841 sec. Processed 58.89 million rows, 80.85 GB (51.80 thousand rows/s., 71.12 MB/s.)
Peak memory usage: 2.51 GiB.
この操作はPostgresにかなりの負荷をかける可能性があります。ユーザーは、運用ワークロードに影響を与えないように、SQLスクリプトをエクスポートするような代替操作でバックフィルすることを検討するかもしれません。この操作のパフォーマンスは、PostgresとClickHouseのクラスターサイズ、およびそのネットワークインターコネクトに依存します。
ClickHouseからPostgresへの各
SELECTは、単一の接続を使用します。この接続は、設定postgresql_connection_pool_size(デフォルト16)でサイズ指定されたサーバー側の接続プールから取られます。
フルデータセットを使用している場合、例では59mの投稿がロードされるはずです。ClickHouseでの簡単なカウントで確認します:
SELECT count()
FROM posts
┌──count()─┐
│ 58889566 │
└──────────┘
型の最適化
このスキーマの型を最適化する手順は、他のソースからデータがロードされた場合と同じです(例: S3のParquet)。Parquetを使用した代替ガイドで説明されているプロセスを適用すると、以下のスキーマが生成されます:
CREATE TABLE posts_v2
(
`Id` Int32,
`PostTypeId` Enum('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
`AcceptedAnswerId` UInt32,
`CreationDate` DateTime,
`Score` Int32,
`ViewCount` UInt32,
`Body` String,
`OwnerUserId` Int32,
`OwnerDisplayName` String,
`LastEditorUserId` Int32,
`LastEditorDisplayName` String,
`LastEditDate` DateTime,
`LastActivityDate` DateTime,
`Title` String,
`Tags` String,
`AnswerCount` UInt16,
`CommentCount` UInt8,
`FavoriteCount` UInt8,
`ContentLicense` LowCardinality(String),
`ParentId` String,
`CommunityOwnedDate` DateTime,
`ClosedDate` DateTime
)
ENGINE = MergeTree
ORDER BY tuple()
COMMENT '最適化されたタイプ'
このテーブルを埋めるには、以前のテーブルからデータを読み取り、このテーブルに挿入するシンプルなINSERT INTO SELECTを使用できます:
INSERT INTO posts_v2 SELECT * FROM posts
0 rows in set. Elapsed: 146.471 sec. Processed 59.82 million rows, 83.82 GB (408.40 thousand rows/s., 572.25 MB/s.)
新しいスキーマでは、nullは保持されません。上記の挿入では、これらをそれぞれのタイプのデフォルト値に暗黙的に変換します。整数は0、文字列は空の値となります。ClickHouseはまた、任意の数値をその目標精度に自動的に変換します。
ClickHouseにおける主(順序)キー
OLTPデータベースから来たユーザーは、多くの場合、ClickHouseでの同等の概念を探します。ClickHouseがPRIMARY KEY構文をサポートしていることに気付くと、ユーザーはOLTPデータベースのソースと同じキーを使用してテーブルスキーマを定義しようとするかもしれませんが、これは適切ではありません。
ClickHouseの主キーはどのように異なるか?
OLTP主キーをClickHouseで使用するのが不適切である理由を理解するには、ClickHouseのインデックス付けの基本を理解する必要があります。ここではPostgresを例として比較しますが、これらの一般的な概念は他のOLTPデータベースにも適用されます。
- Postgresの主キーは、定義上、行ごとに一意です。B-tree構造を使用することで、このキーによる単一行の効率的な検索を可能にします。ClickHouseは単一行の値の検索に最適化できますが、分析ワークロードでは通常、多くの行に対して一部のカラムを読み取ることが求められます。フィルターは、集計が行われる行のサブセットを特定する必要があります。
- メモリとディスクの効率は、ClickHouseが頻繁に使用されるスケールでは非常に重要です。データは、ClickHouseテーブルにパーツとして知られるチャンクに書き込まれ、バックグラウンドでパーツをマージするルールが適用されます。ClickHouseでは、各パーツに独自の主インデックスがあります。パーツがマージされると、マージされたパーツの主インデックスもマージされます。Postgresとは異なり、これらのインデックスは各行に対して構築されません。代わりに、パーツの主インデックスは、行のグループごとに1つのインデックスエントリを持ち、この技術はスパースインデックスと呼ばれます。
- スパースインデックスは、ClickHouseがゆえに可能です。ClickHouseは、指定されたキーによってディスク上に並べられたデータを記憶します。その結果、スパース主インデックスは、インデックスエントリに対してバイナリサーチを介してクエリと一致する可能性のある行のグループを迅速に特定できます。特定された可能性のあるマッチング行のグループは、その後、ClickHouseエンジンに並行してストリーミングされ、マッチを見つけます。このインデックス設計により、主インデックスが小さく(完全にメインメモリに収まる)状態を保ちながら、特にデータ分析のユースケースに典型的な範囲クエリの実行時間を大幅に高速化します。詳細については、この詳細なガイドをお勧めします。
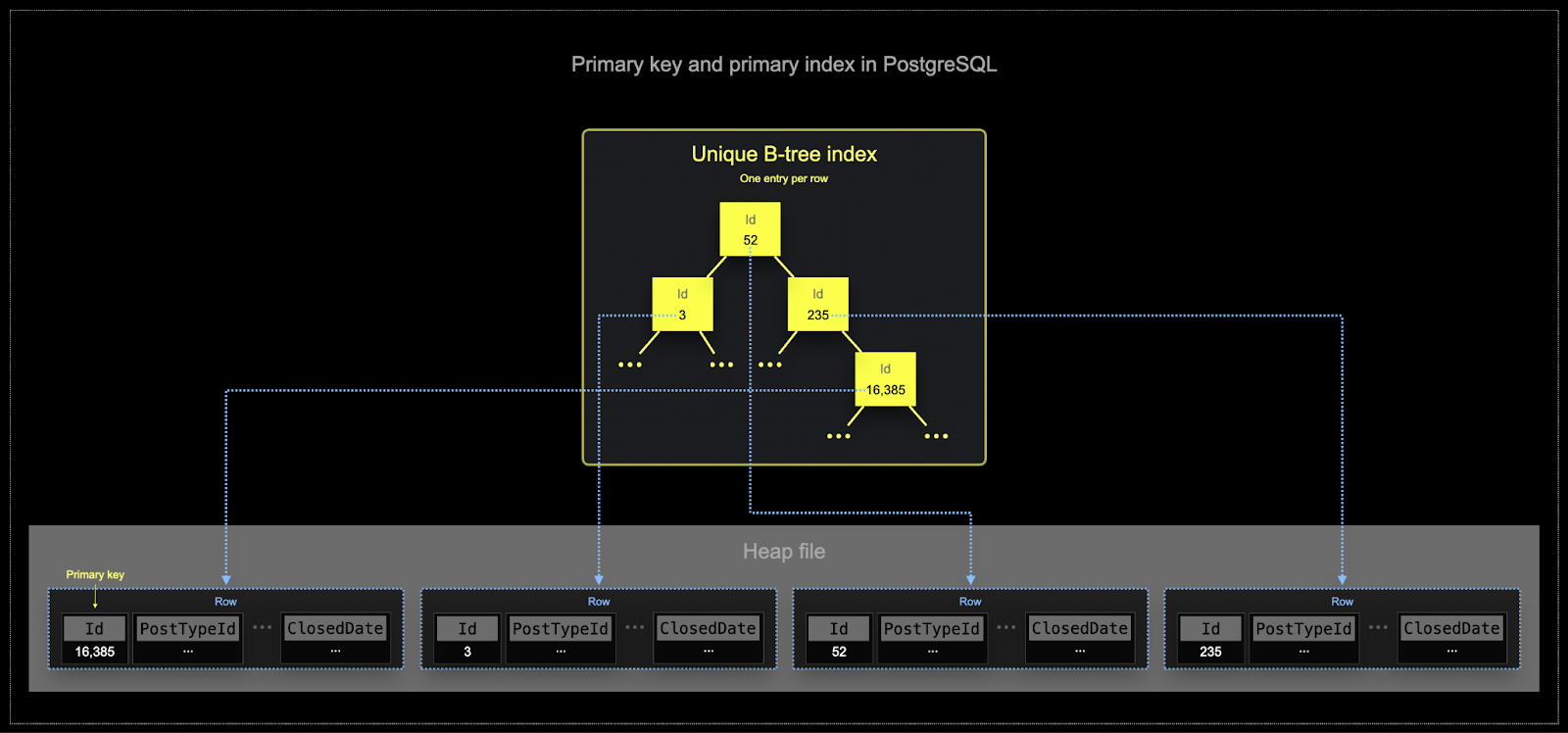
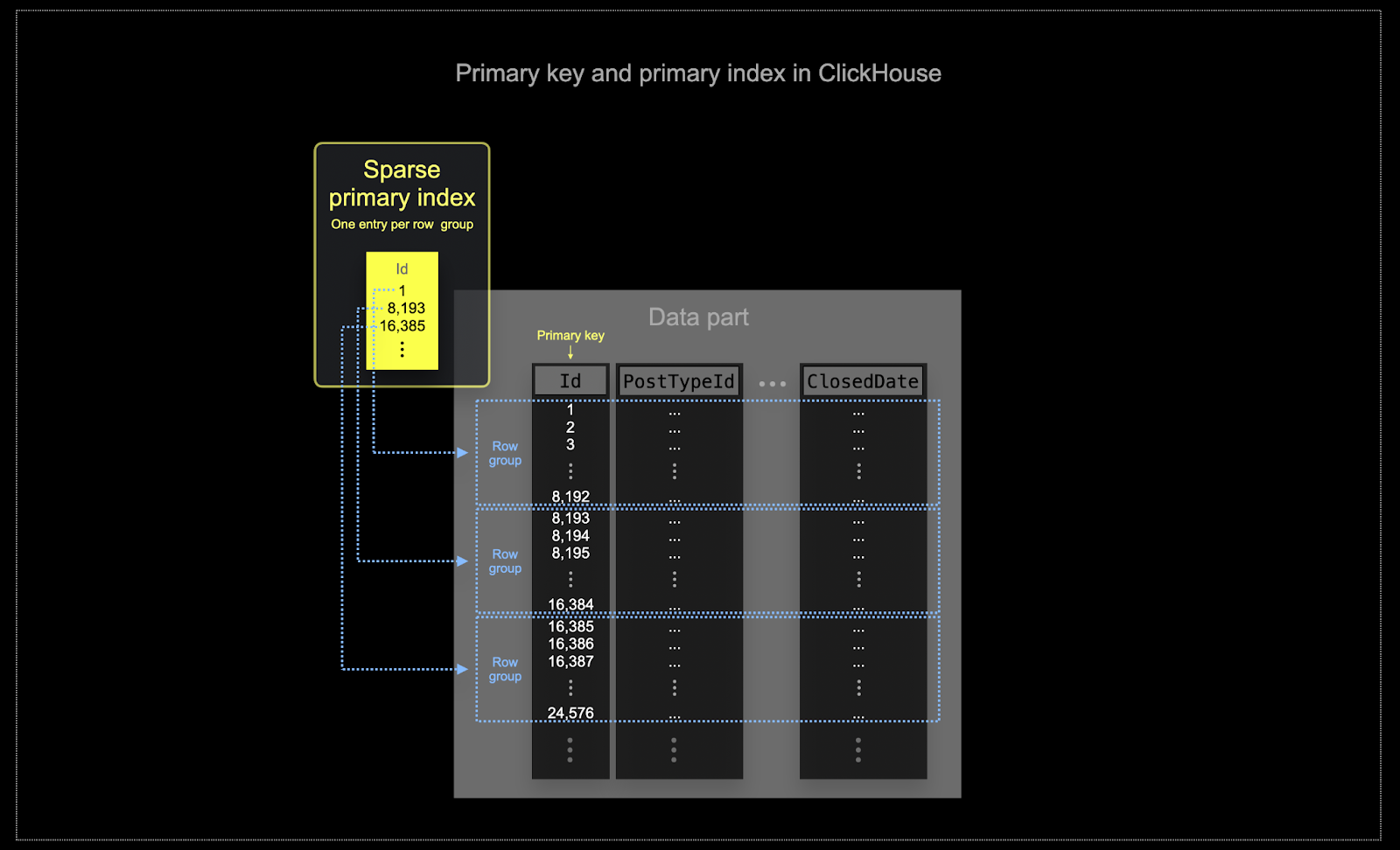
ClickHouseで選択されたキーは、インデックスだけでなく、ディスクに書き込まれるデータの順序も決定します。したがって、圧縮レベルに大きな影響を与える可能性があり、それが結果的にクエリのパフォーマンスに影響を与える可能性があります。大部分のカラムの値が連続して書き込まれるような順序キーは、選択された圧縮アルゴリズム(およびコーデック)がデータをより効果的に圧縮するのを可能にします。
テーブル内の全てのカラムは、指定された順序キーの値に基づいてソートされます。たとえそれがキー自体には含まれていなくてもです。例えば、
CreationDateがキーとして使用されている場合、他の全てのカラムの値の順序は、CreationDateカラムの値の順序と一致します。複数の順序キーを指定することができ、これはSELECTクエリのORDER BY句と同じセマンティクスで順序付けされます。
順序キーの選択
順序キーの選択における考慮事項とステップについては、postsテーブルを例にこちらを参照してください。
圧縮
ClickHouseの列指向ストレージは、Postgresと比較して圧縮が大幅に向上することがあります。以下は、両方のデータベースでStack Overflowテーブル全体のストレージ要件を比較したものです:
--Postgres
SELECT
schemaname,
tablename,
pg_total_relation_size(schemaname || '.' || tablename) AS total_size_bytes,
pg_total_relation_size(schemaname || '.' || tablename) / (1024 * 1024 * 1024) AS total_size_gb
FROM
pg_tables s
WHERE
schemaname = 'public';
schemaname | tablename | total_size_bytes | total_size_gb |
------------+-----------------+------------------+---------------+
public | users | 4288405504 | 3 |
public | posts | 68606214144 | 63 |
public | votes | 20525654016 | 19 |
public | comments | 22888538112 | 21 |
public | posthistory | 125899735040 | 117 |
public | postlinks | 579387392 | 0 |
public | badges | 4989747200 | 4 |
(7 rows)
--ClickHouse
SELECT
`table`,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_size
FROM system.parts
WHERE (database = 'stackoverflow') AND active
GROUP BY `table`
┌─table───────┬─compressed_size─┐
│ posts │ 25.17 GiB │
│ users │ 846.57 MiB │
│ badges │ 513.13 MiB │
│ comments │ 7.11 GiB │
│ votes │ 1.28 GiB │
│ posthistory │ 40.44 GiB │
│ postlinks │ 79.22 MiB │
└─────────────┴─────────────────┘
圧縮を最適化し、測定する方法についての詳細はこちらにて確認できます。