RedshiftからClickHouseへのデータ移行
関連コンテンツ
はじめに
Amazon Redshift は、Amazon Web Services の提供の一部である人気のクラウドデータウェアハウジングソリューションです。このガイドでは、RedshiftインスタンスからClickHouseへのデータ移行のためのさまざまなアプローチを紹介します。以下の3つのオプションをカバーします。
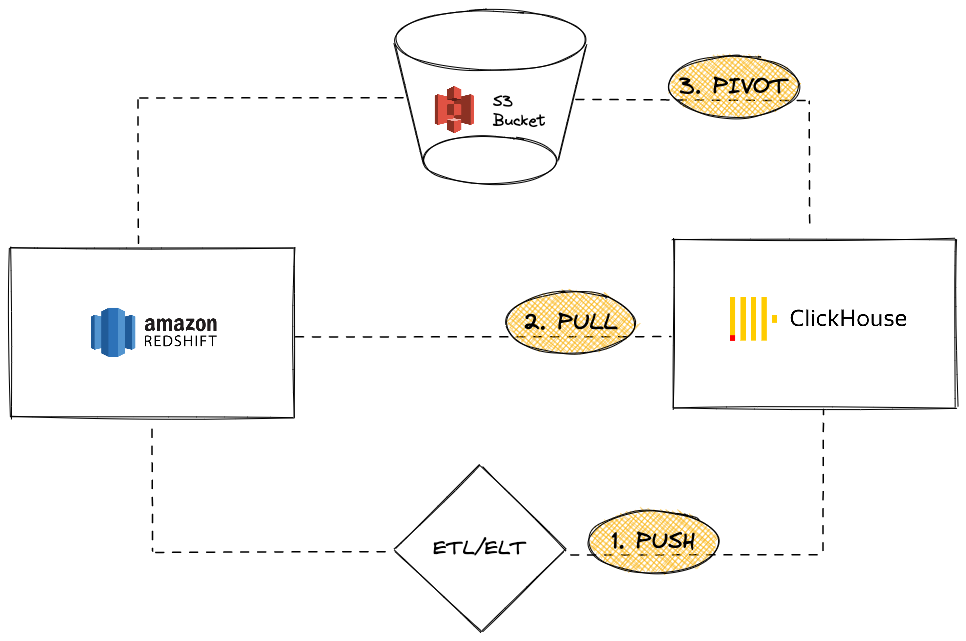
ClickHouse インスタンスの観点からは、次のいずれかの方法で移行できます:
RedshiftからClickHouseへデータをPUSHする サードパーティのETL/ELTツールやサービスを使用してClickHouseにデータを送信する
RedshiftからClickHouseへデータをPULLする ClickHouse JDBC Bridgeを活用してRedshiftからデータを取得する
S3を使用してRedshiftからClickHouseへデータをPIVOTする S3オブジェクトストレージを使用して「アンロードしてロードする」ロジックを適用する
このチュートリアルではデータソースとしてRedshiftを使用しましたが、ここで紹介する移行アプローチはRedshiftに限定されず、その他の互換性のあるデータソースにも類似した手順を適用できます。
RedshiftからClickHouseへデータをPUSHする
プッシュのシナリオでは、サードパーティのツールやサービス(カスタムコードやETL/ELTを使用するかのいずれか)を活用して、データをClickHouseインスタンスに送るという考え方です。例えば、Airbyteのようなソフトウェアを使用して、Redshiftインスタンス(ソースとして)からClickHouse(デスティネーションとして)にデータを移動することができます(Airbyteとの統合ガイドを参照)。

利点
- ETL/ELTソフトウェアの既存のコネクタカタログを活用できます。
- データを同期させるための組み込み機能(追加/上書き/インクリメントロジック)があります。
- データ変換シナリオを可能にします(例として、dbtとの統合ガイドを参照)。
欠点
- ユーザーはETL/ELTインフラストラクチャのセットアップと保守が必要です。
- アーキテクチャにサードパーティ要素を導入することで、潜在的なスケーラビリティのボトルネックとなる可能性があります。
RedshiftからClickHouseへデータをPULLする
プルのシナリオでは、ClickHouse JDBC Bridgeを活用して、ClickHouseインスタンスから直接Redshiftクラスタに接続し、INSERT INTO ... SELECT クエリを実行します。

利点
- JDBC互換のすべてのツールに対して汎用的です。
- ClickHouseから複数の外部データソースをクエリできる優雅なソリューションです。
欠点
- ClickHouse JDBC Bridgeインスタンスが必要で、これが潜在的なスケーラビリティのボトルネックになる可能性があります。
RedshiftはPostgreSQLベースですが、ClickHouseのPostgreSQLテーブル関数やテーブルエンジンを使用することはできません。なぜならClickHouseはPostgreSQLバージョン9以上を必要とし、Redshift APIはそれ以前のバージョン(8.x)に基づいているからです。
チュートリアル
このオプションを使用するには、ClickHouse JDBC Bridgeをセットアップする必要があります。ClickHouse JDBC Bridgeは、JDBC接続を処理し、ClickHouseインスタンスとデータソース間のプロキシとして機能するスタンドアロンのJavaアプリケーションです。このチュートリアルでは、サンプルデータベースを持つ事前にポピュレートされたRedshiftインスタンスを使用しました。
- ClickHouse JDBC Bridgeをデプロイします。詳細については、外部データソース用のJDBCに関するユーザーガイドを参照してください。
ClickHouse Cloudを使用している場合は、ClickHouse JDBC Bridgeを別の環境で実行し、remoteSecure関数を使用してClickHouse Cloudに接続する必要があります。
ClickHouse JDBC Bridge用にRedshiftデータソースを設定します。例えば、
/etc/clickhouse-jdbc-bridge/config/datasources/redshift.json{
"redshift-server": {
"aliases": [
"redshift"
],
"driverUrls": [
"https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/2.1.0.4/redshift-jdbc42-2.1.0.4.jar"
],
"driverClassName": "com.amazon.redshift.jdbc.Driver",
"jdbcUrl": "jdbc:redshift://redshift-cluster-1.ckubnplpz1uv.us-east-1.redshift.amazonaws.com:5439/dev",
"username": "awsuser",
"password": "<password>",
"maximumPoolSize": 5
}
}ClickHouse JDBC Bridgeがデプロイされ実行中になったら、ClickHouseからRedshiftインスタンスをクエリし始めることができます。
SELECT *
FROM jdbc('redshift', 'select username, firstname, lastname from users limit 5')Query id: 1b7de211-c0f6-4117-86a2-276484f9f4c0
┌─username─┬─firstname─┬─lastname─┐
│ PGL08LJI │ Vladimir │ Humphrey │
│ XDZ38RDD │ Barry │ Roy │
│ AEB55QTM │ Reagan │ Hodge │
│ OWY35QYB │ Tamekah │ Juarez │
│ MSD36KVR │ Mufutau │ Watkins │
└──────────┴───────────┴──────────┘
5 rows in set. Elapsed: 0.438 sec.SELECT *
FROM jdbc('redshift', 'select count(*) from sales')Query id: 2d0f957c-8f4e-43b2-a66a-cc48cc96237b
┌──count─┐
│ 172456 │
└────────┘
1 rows in set. Elapsed: 0.304 sec.以下に、
INSERT INTO ... SELECT文を使用してデータをインポートする例を示します。# 3カラムを持つテーブル作成
CREATE TABLE users_imported
(
`username` String,
`firstname` String,
`lastname` String
)
ENGINE = MergeTree
ORDER BY firstnameQuery id: c7c4c44b-cdb2-49cf-b319-4e569976ab05
Ok.
0 rows in set. Elapsed: 0.233 sec.# データのインポート
INSERT INTO users_imported (*) SELECT *
FROM jdbc('redshift', 'select username, firstname, lastname from users')Query id: 9d3a688d-b45a-40f4-a7c7-97d93d7149f1
Ok.
0 rows in set. Elapsed: 4.498 sec. Processed 49.99 thousand rows, 2.49 MB (11.11 thousand rows/s., 554.27 KB/s.)
S3を使用してRedshiftからClickHouseへデータをPIVOTする
このシナリオでは、中間ピボットフォーマットでデータをS3にエクスポートし、次のステップでClickHouseにデータをロードします。
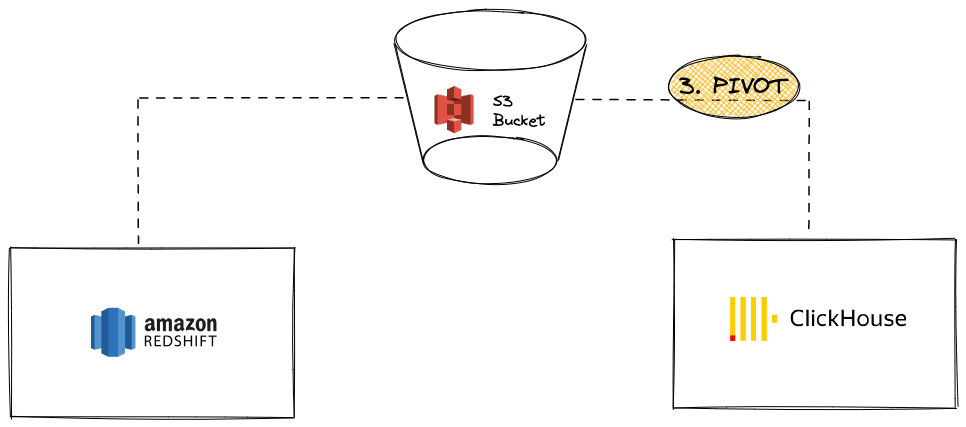
利点
- RedshiftとClickHouseの両方が強力なS3統合機能を持っています。
- Redshiftの
UNLOADコマンドとClickHouse S3テーブル関数/テーブルエンジンのような既存の機能を活用します。 - ClickHouseでの並列リードとS3との間の高いスループット能力のおかげでシームレスにスケールします。
- Apache Parquetのような高度で圧縮されたフォーマットを活用できます。
欠点
- プロセスが2ステップになる(Redshiftからアンロードし、その後ClickHouseにロード)。
チュートリアル
RedshiftのUNLOAD機能を使用して、既存のプライベートS3バケットにデータをエクスポートします。
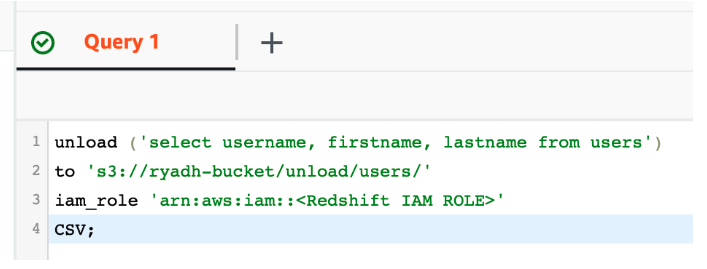
これにより、S3には生データを含むパートファイルが生成されます。

ClickHouseでテーブルを作成します。
CREATE TABLE users
(
username String,
firstname String,
lastname String
)
ENGINE = MergeTree
ORDER BY usernameあるいは、ClickHouseは
CREATE TABLE ... EMPTY AS SELECTを使用してテーブル構造を推測しようとすることもできます。CREATE TABLE users
ENGINE = MergeTree ORDER BY username
EMPTY AS
SELECT * FROM s3('https://your-bucket.s3.amazonaws.com/unload/users/*', '<aws_access_key>', '<aws_secret_access_key>', 'CSV')これは特に、Parquetのようにデータ型に関する情報を含むフォーマットでデータがある場合にうまく機能します。
INSERT INTO ... SELECTステートメントを使用して、ClickHouseにS3ファイルをロードします。INSERT INTO users SELECT *
FROM s3('https://your-bucket.s3.amazonaws.com/unload/users/*', '<aws_access_key>', '<aws_secret_access_key>', 'CSV')Query id: 2e7e219a-6124-461c-8d75-e4f5002c8557
Ok.
0 rows in set. Elapsed: 0.545 sec. Processed 49.99 thousand rows, 2.34 MB (91.72 thousand rows/s., 4.30 MB/s.)
この例では、ピボットフォーマットとしてCSVを使用しました。しかし、本番環境のワークロードの場合、大規模な移行に適した選択肢として、Apache Parquetを推奨します。Parquetは圧縮を伴い、ストレージコストを削減し、転送時間を短縮することができます(デフォルトでは、各ロウグループはSNAPPYを使用して圧縮されています)。ClickHouseはまた、データのインジェストを高速化するためにParquetの列指向を活用しています。