高度なチュートリアル
このチュートリアルから何を期待できますか?
このチュートリアルでは、テーブルを作成し、大規模なデータセット(二百万行のニューヨークのタクシーデータ)を挿入します。その後、データセットに対してクエリを実行し、Dictionaryを作成してJOINを実行する例を含めます。
このチュートリアルは、稼働中のClickHouseサービスにアクセスできることを前提としています。もしない場合は、クイックスタートをご覧ください。
1. 新しいテーブルを作成する
ニューヨーク市のタクシーデータには、数百万のタクシー乗車の詳細が含まれており、乗車と降車の時間と場所、料金、チップの金額、通行料、支払い方法などがカラムとして含まれています。このデータを保存するテーブルを作成しましょう...
SQLコンソールに接続する
SQL コンソールSQL クライアント接続が必要な場合、ClickHouse Cloud サービスには関連付けられたウェブベースの SQL コンソールがあります。詳細については、以下の SQL コンソールに接続 を展開してください。
SQL コンソールに接続
ClickHouse Cloud サービス一覧から、作業するサービスを選択し、接続 をクリックします。ここから SQL コンソールを開く ことができます:
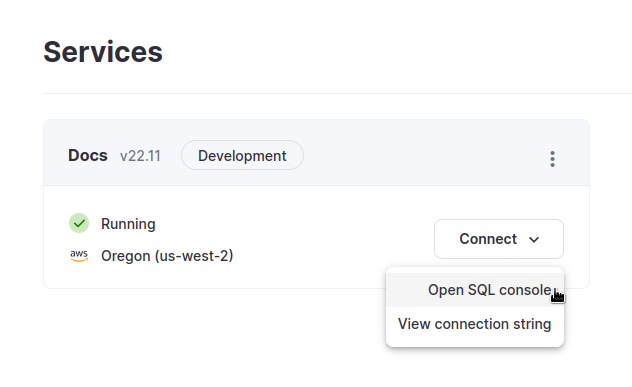
セルフマネージドのClickHouseを使用している場合は、https://hostname:8443/playでSQLコンソールに接続できます(詳細はClickHouse管理者にお問い合わせください)。
defaultデータベースに次のtripsテーブルを作成します:CREATE TABLE trips
(
`trip_id` UInt32,
`vendor_id` Enum8('1' = 1, '2' = 2, '3' = 3, '4' = 4, 'CMT' = 5, 'VTS' = 6, 'DDS' = 7, 'B02512' = 10, 'B02598' = 11, 'B02617' = 12, 'B02682' = 13, 'B02764' = 14, '' = 15),
`pickup_date` Date,
`pickup_datetime` DateTime,
`dropoff_date` Date,
`dropoff_datetime` DateTime,
`store_and_fwd_flag` UInt8,
`rate_code_id` UInt8,
`pickup_longitude` Float64,
`pickup_latitude` Float64,
`dropoff_longitude` Float64,
`dropoff_latitude` Float64,
`passenger_count` UInt8,
`trip_distance` Float64,
`fare_amount` Float32,
`extra` Float32,
`mta_tax` Float32,
`tip_amount` Float32,
`tolls_amount` Float32,
`ehail_fee` Float32,
`improvement_surcharge` Float32,
`total_amount` Float32,
`payment_type` Enum8('UNK' = 0, 'CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4),
`trip_type` UInt8,
`pickup` FixedString(25),
`dropoff` FixedString(25),
`cab_type` Enum8('yellow' = 1, 'green' = 2, 'uber' = 3),
`pickup_nyct2010_gid` Int8,
`pickup_ctlabel` Float32,
`pickup_borocode` Int8,
`pickup_ct2010` String,
`pickup_boroct2010` String,
`pickup_cdeligibil` String,
`pickup_ntacode` FixedString(4),
`pickup_ntaname` String,
`pickup_puma` UInt16,
`dropoff_nyct2010_gid` UInt8,
`dropoff_ctlabel` Float32,
`dropoff_borocode` UInt8,
`dropoff_ct2010` String,
`dropoff_boroct2010` String,
`dropoff_cdeligibil` String,
`dropoff_ntacode` FixedString(4),
`dropoff_ntaname` String,
`dropoff_puma` UInt16
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(pickup_date)
ORDER BY pickup_datetime;
2. データセットを挿入する
テーブルを作成したので、NYCタクシーデータを追加しましょう。このデータはS3内のCSVファイルにあり、そこからデータをロードできます。
次のコマンドにより、2つの異なるS3ファイル
trips_1.tsv.gzとtrips_2.tsv.gzからtripsテーブルに約2,000,000行を挿入します:INSERT INTO trips
SELECT * FROM s3(
'https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_{1..2}.gz',
'TabSeparatedWithNames', "
`trip_id` UInt32,
`vendor_id` Enum8('1' = 1, '2' = 2, '3' = 3, '4' = 4, 'CMT' = 5, 'VTS' = 6, 'DDS' = 7, 'B02512' = 10, 'B02598' = 11, 'B02617' = 12, 'B02682' = 13, 'B02764' = 14, '' = 15),
`pickup_date` Date,
`pickup_datetime` DateTime,
`dropoff_date` Date,
`dropoff_datetime` DateTime,
`store_and_fwd_flag` UInt8,
`rate_code_id` UInt8,
`pickup_longitude` Float64,
`pickup_latitude` Float64,
`dropoff_longitude` Float64,
`dropoff_latitude` Float64,
`passenger_count` UInt8,
`trip_distance` Float64,
`fare_amount` Float32,
`extra` Float32,
`mta_tax` Float32,
`tip_amount` Float32,
`tolls_amount` Float32,
`ehail_fee` Float32,
`improvement_surcharge` Float32,
`total_amount` Float32,
`payment_type` Enum8('UNK' = 0, 'CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4),
`trip_type` UInt8,
`pickup` FixedString(25),
`dropoff` FixedString(25),
`cab_type` Enum8('yellow' = 1, 'green' = 2, 'uber' = 3),
`pickup_nyct2010_gid` Int8,
`pickup_ctlabel` Float32,
`pickup_borocode` Int8,
`pickup_ct2010` String,
`pickup_boroct2010` String,
`pickup_cdeligibil` String,
`pickup_ntacode` FixedString(4),
`pickup_ntaname` String,
`pickup_puma` UInt16,
`dropoff_nyct2010_gid` UInt8,
`dropoff_ctlabel` Float32,
`dropoff_borocode` UInt8,
`dropoff_ct2010` String,
`dropoff_boroct2010` String,
`dropoff_cdeligibil` String,
`dropoff_ntacode` FixedString(4),
`dropoff_ntaname` String,
`dropoff_puma` UInt16
") SETTINGS input_format_try_infer_datetimes = 0INSERTが完了するのを待ちます。150 MBのデータがダウンロードされるのに少し時間がかかるかもしれません。Notes3関数はデータを自動的に解凍する方法を知っており、TabSeparatedWithNamesフォーマットはデータがタブ区切りであり、各ファイルのヘッダー行をスキップするようClickHouseに指示します。挿入が終了したら、それが正常に動作したか確認してください:
SELECT count() FROM trips約2M行(厳密には1,999,657行)を見ることができるはずです。
NoteClickHouseがカウントを決定するために処理しなければならなかった行数と、どれほど迅速であるか注意してください。わずか0.001秒で6行だけ処理してカウントを取得できます。(その6は、
tripsテーブルが現在持つ パーツ の数であり、パーツは自身の行数を知っています。)すべての行をクロールする必要があるクエリを実行すると、処理する行数が大幅に増加することに気付くでしょうが、実行時間は依然として非常に速いままです:
SELECT DISTINCT(pickup_ntaname) FROM tripsこのクエリは2M行を処理し、190の値を返す必要がありますが、約1秒でそれを行います。
pickup_ntanameカラムは、タクシー乗車が始まったニューヨーク市の地域の名前を表します。
3. データを分析する
2M行のデータを分析するクエリをいくつか実行してみましょう...
まず、平均チップ額を計算するような簡単な計算から始めます:
SELECT round(avg(tip_amount), 2) FROM trips応答は以下のとおりです:
┌─round(avg(tip_amount), 2)─┐
│ 1.68 │
└───────────────────────────┘次のクエリは、乗客数に基づいた平均費用を計算します:
SELECT
passenger_count,
ceil(avg(total_amount),2) AS average_total_amount
FROM trips
GROUP BY passenger_countpassenger_countの範囲は0から9までです:┌─passenger_count─┬─average_total_amount─┐
│ 0 │ 22.69 │
│ 1 │ 15.97 │
│ 2 │ 17.15 │
│ 3 │ 16.76 │
│ 4 │ 17.33 │
│ 5 │ 16.35 │
│ 6 │ 16.04 │
│ 7 │ 59.8 │
│ 8 │ 36.41 │
│ 9 │ 9.81 │
└─────────────────┴──────────────────────┘ここでは、地域ごとの日次乗車数を計算するクエリがあります:
SELECT
pickup_date,
pickup_ntaname,
SUM(1) AS number_of_trips
FROM trips
GROUP BY pickup_date, pickup_ntaname
ORDER BY pickup_date ASC結果は以下のようになります:
┌─pickup_date─┬─pickup_ntaname───────────────────────────────────────────┬─number_of_trips─┐
│ 2015-07-01 │ Brooklyn Heights-Cobble Hill │ 13 │
│ 2015-07-01 │ Old Astoria │ 5 │
│ 2015-07-01 │ Flushing │ 1 │
│ 2015-07-01 │ Yorkville │ 378 │
│ 2015-07-01 │ Gramercy │ 344 │
│ 2015-07-01 │ Fordham South │ 2 │
│ 2015-07-01 │ SoHo-TriBeCa-Civic Center-Little Italy │ 621 │
│ 2015-07-01 │ Park Slope-Gowanus │ 29 │
│ 2015-07-01 │ Bushwick South │ 5 │このクエリは、旅行時間を計算し、その値で結果をグループ化します:
SELECT
avg(tip_amount) AS avg_tip,
avg(fare_amount) AS avg_fare,
avg(passenger_count) AS avg_passenger,
count() AS count,
truncate(date_diff('second', pickup_datetime, dropoff_datetime)/60) as trip_minutes
FROM trips
WHERE trip_minutes > 0
GROUP BY trip_minutes
ORDER BY trip_minutes DESC結果は以下のようになります:
┌──────────────avg_tip─┬───────────avg_fare─┬──────avg_passenger─┬──count─┬─trip_minutes─┐
│ 1.9600000381469727 │ 8 │ 1 │ 1 │ 27511 │
│ 0 │ 12 │ 2 │ 1 │ 27500 │
│ 0.542166673981895 │ 19.716666666666665 │ 1.9166666666666667 │ 60 │ 1439 │
│ 0.902499997522682 │ 11.270625001192093 │ 1.95625 │ 160 │ 1438 │
│ 0.9715789457909146 │ 13.646616541353383 │ 2.0526315789473686 │ 133 │ 1437 │
│ 0.9682692398245518 │ 14.134615384615385 │ 2.076923076923077 │ 104 │ 1436 │
│ 1.1022105210705808 │ 13.778947368421052 │ 2.042105263157895 │ 95 │ 1435 │このクエリは各時間帯の地域ごとの乗車数を表示します:
SELECT
pickup_ntaname,
toHour(pickup_datetime) as pickup_hour,
SUM(1) AS pickups
FROM trips
WHERE pickup_ntaname != ''
GROUP BY pickup_ntaname, pickup_hour
ORDER BY pickup_ntaname, pickup_hour結果は以下のようになります:
┌─pickup_ntaname───────────────────────────────────────────┬─pickup_hour─┬─pickups─┐
│ Airport │ 0 │ 3509 │
│ Airport │ 1 │ 1184 │
│ Airport │ 2 │ 401 │
│ Airport │ 3 │ 152 │
│ Airport │ 4 │ 213 │
│ Airport │ 5 │ 955 │
│ Airport │ 6 │ 2161 │
│ Airport │ 7 │ 3013 │
│ Airport │ 8 │ 3601 │
│ Airport │ 9 │ 3792 │
│ Airport │ 10 │ 4546 │
│ Airport │ 11 │ 4659 │
│ Airport │ 12 │ 4621 │
│ Airport │ 13 │ 5348 │
│ Airport │ 14 │ 5889 │
│ Airport │ 15 │ 6505 │
│ Airport │ 16 │ 6119 │
│ Airport │ 17 │ 6341 │
│ Airport │ 18 │ 6173 │
│ Airport │ 19 │ 6329 │
│ Airport │ 20 │ 6271 │
│ Airport │ 21 │ 6649 │
│ Airport │ 22 │ 6356 │
│ Airport │ 23 │ 6016 │
│ Allerton-Pelham Gardens │ 4 │ 1 │
│ Allerton-Pelham Gardens │ 6 │ 1 │
│ Allerton-Pelham Gardens │ 7 │ 1 │
│ Allerton-Pelham Gardens │ 9 │ 5 │
│ Allerton-Pelham Gardens │ 10 │ 3 │
│ Allerton-Pelham Gardens │ 15 │ 1 │
│ Allerton-Pelham Gardens │ 20 │ 2 │
│ Allerton-Pelham Gardens │ 23 │ 1 │
│ Annadale-Huguenot-Prince's Bay-Eltingville │ 23 │ 1 │
│ Arden Heights │ 11 │ 1 │ラガーディア(LGA)またはJFK空港への移動を見てみましょう:
SELECT
pickup_datetime,
dropoff_datetime,
total_amount,
pickup_nyct2010_gid,
dropoff_nyct2010_gid,
CASE
WHEN dropoff_nyct2010_gid = 138 THEN 'LGA'
WHEN dropoff_nyct2010_gid = 132 THEN 'JFK'
END AS airport_code,
EXTRACT(YEAR FROM pickup_datetime) AS year,
EXTRACT(DAY FROM pickup_datetime) AS day,
EXTRACT(HOUR FROM pickup_datetime) AS hour
FROM trips
WHERE dropoff_nyct2010_gid IN (132, 138)
ORDER BY pickup_datetime応答は以下のとおりです:
┌─────pickup_datetime─┬────dropoff_datetime─┬─total_amount─┬─pickup_nyct2010_gid─┬─dropoff_nyct2010_gid─┬─airport_code─┬─year─┬─day─┬─hour─┐
│ 2015-07-01 00:04:14 │ 2015-07-01 00:15:29 │ 13.3 │ -34 │ 132 │ JFK │ 2015 │ 1 │ 0 │
│ 2015-07-01 00:09:42 │ 2015-07-01 00:12:55 │ 6.8 │ 50 │ 138 │ LGA │ 2015 │ 1 │ 0 │
│ 2015-07-01 00:23:04 │ 2015-07-01 00:24:39 │ 4.8 │ -125 │ 132 │ JFK │ 2015 │ 1 │ 0 │
│ 2015-07-01 00:27:51 │ 2015-07-01 00:39:02 │ 14.72 │ -101 │ 138 │ LGA │ 2015 │ 1 │ 0 │
│ 2015-07-01 00:32:03 │ 2015-07-01 00:55:39 │ 39.34 │ 48 │ 138 │ LGA │ 2015 │ 1 │ 0 │
│ 2015-07-01 00:34:12 │ 2015-07-01 00:40:48 │ 9.95 │ -93 │ 132 │ JFK │ 2015 │ 1 │ 0 │
│ 2015-07-01 00:38:26 │ 2015-07-01 00:49:00 │ 13.3 │ -11 │ 138 │ LGA │ 2015 │ 1 │ 0 │
│ 2015-07-01 00:41:48 │ 2015-07-01 00:44:45 │ 6.3 │ -94 │ 132 │ JFK │ 2015 │ 1 │ 0 │
│ 2015-07-01 01:06:18 │ 2015-07-01 01:14:43 │ 11.76 │ 37 │ 132 │ JFK │ 2015 │ 1 │ 1 │
4. Dictionaryを作成する
ClickHouse初心者の方は、Dictionaryの動作を理解することが重要です。Dictionaryを考えるシンプルな方法は、メモリ内に格納されたキー->値のペアのマッピングです。詳細やDictionaryのすべてのオプションはチュートリアルの最後にリンクされています。
ClickHouseサービス内のテーブルに関連付けられたDictionaryを作成する方法を見てみましょう。表とそのDictionaryは、NYCの各地域を示す265行のCSVファイルに基づきます。これらの地域はニューヨーク市の各行政区の名前にマッピングされており(ニューヨーク市には5つの行政区があります:ブロンクス、ブルックリン、マンハッタン、クイーンズ、スタテンアイランド)、このファイルはニューアーク空港(EWR)も1つの行政区として数えます。
これはCSVファイルの一部です(明確にするために表として表示されています)。ファイル内の
LocationIDカラムは、tripsテーブル内のpickup_nyct2010_gidとdropoff_nyct2010_gidカラムにマッピングされます:LocationID Borough Zone service_zone 1 EWR Newark Airport EWR 2 Queens Jamaica Bay Boro Zone 3 Bronx Allerton/Pelham Gardens Boro Zone 4 Manhattan Alphabet City Yellow Zone 5 Staten Island Arden Heights Boro Zone ファイルのURLは
https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/taxi_zone_lookup.csvです。次のSQLを実行してください、これはtaxi_zone_dictionaryという名のDictionaryを作成し、S3のCSVファイルからDictionaryを読み込みます:CREATE DICTIONARY taxi_zone_dictionary
(
`LocationID` UInt16 DEFAULT 0,
`Borough` String,
`Zone` String,
`service_zone` String
)
PRIMARY KEY LocationID
SOURCE(HTTP(URL 'https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/taxi_zone_lookup.csv' FORMAT 'CSVWithNames'))
LIFETIME(MIN 0 MAX 0)
LAYOUT(HASHED_ARRAY())NoteLIFETIMEを0に設定することで、Dictionaryはソースとともに更新されることはありません。ここでは不要なトラフィックをS3バケットに送らないように使用されていますが、一般的には任意のLifetime値を指定できます。例えば:
LIFETIME(MIN 1 MAX 10)と設定すると、辞書は1秒から10秒の間のランダムな時間後に更新されます。(ランダムな時間は、多数のサーバーでの更新時に辞書ソースへの負荷を分散するために必要です。)
正常に動作した事を確認してください - あなたは265行(各地域ごとに1行)を取得します:
SELECT * FROM taxi_zone_dictionarydictGet関数(およびそのバリエーション)を使用してDictionaryから値を取得します。辞書の名前、取得したい値、およびキー(この例ではtaxi_zone_dictionaryのLocationIDカラム)を渡します。例えば、以下のクエリは、
LocationIDが132であるBoroughを返します(これは上で見たようにJFK空港です):SELECT dictGet('taxi_zone_dictionary', 'Borough', 132)JFKはクイーンズにあり、値を取得する時間は本質的に0であることに注意してください:
┌─dictGet('taxi_zone_dictionary', 'Borough', 132)─┐
│ Queens │
└─────────────────────────────────────────────────┘
1 rows in set. Elapsed: 0.004 sec.dictHas関数を使用してDictionaryにキーが存在するかどうかを確認します。たとえば、次のクエリは1を返します(これはClickHouseでの"true"に相当します):SELECT dictHas('taxi_zone_dictionary', 132)次のクエリは、辞書に
LocationIDの値4567がないため、0を返します:SELECT dictHas('taxi_zone_dictionary', 4567)クエリで辞書の名称を取得するために
dictGet関数を使用します。例えば:SELECT
count(1) AS total,
dictGetOrDefault('taxi_zone_dictionary','Borough', toUInt64(pickup_nyct2010_gid), 'Unknown') AS borough_name
FROM trips
WHERE dropoff_nyct2010_gid = 132 OR dropoff_nyct2010_gid = 138
GROUP BY borough_name
ORDER BY total DESCこのクエリは、ラガーディアまたはJFK空港で終わるタクシー乗車の区分を合計します。結果は以下のようになり、出発地域が不明なトリップがかなりあることに注意してください:
┌─total─┬─borough_name──┐
│ 23683 │ Unknown │
│ 7053 │ Manhattan │
│ 6828 │ Brooklyn │
│ 4458 │ Queens │
│ 2670 │ Bronx │
│ 554 │ Staten Island │
│ 53 │ EWR │
└───────┴───────────────┘
7 rows in set. Elapsed: 0.019 sec. Processed 2.00 million rows, 4.00 MB (105.70 million rows/s., 211.40 MB/s.)
5. Joinを実行する
それでは、taxi_zone_dictionaryとtripsテーブルを結合するクエリを何本か書いてみましょう。
単純な
JOINから始めましょう。これは前述の空港クエリと似ています:SELECT
count(1) AS total,
Borough
FROM trips
JOIN taxi_zone_dictionary ON toUInt64(trips.pickup_nyct2010_gid) = taxi_zone_dictionary.LocationID
WHERE dropoff_nyct2010_gid = 132 OR dropoff_nyct2010_gid = 138
GROUP BY Borough
ORDER BY total DESC応答はおなじみのものです:
┌─total─┬─Borough───────┐
│ 7053 │ Manhattan │
│ 6828 │ Brooklyn │
│ 4458 │ Queens │
│ 2670 │ Bronx │
│ 554 │ Staten Island │
│ 53 │ EWR │
└───────┴───────────────┘
6 rows in set. Elapsed: 0.034 sec. Processed 2.00 million rows, 4.00 MB (59.14 million rows/s., 118.29 MB/s.)Note上記の
JOINクエリの出力は、前述のdictGetOrDefaultを使用したクエリと同じです(Unknown値が含まれていないことを除いて)。裏では、ClickHouseは実際にtaxi_zone_dictionary辞書に対してdictGet関数を呼び出していますが、JOIN構文はSQL開発者にとってより親しみやすいものです。ClickHouseでは
SELECT *をあまり使用しません - 必要なカラムのみを取得すべきです!しかし、長時間実行されるクエリを見つけるのは困難なので、このクエリはすべてのカラムを選択し、すべての行を返す(ただしデフォルトで応答には最大10,000行の制限があります)、さらにすべての行を辞書と右結合することを意図的に行います:SELECT *
FROM trips
JOIN taxi_zone_dictionary
ON trips.dropoff_nyct2010_gid = taxi_zone_dictionary.LocationID
WHERE tip_amount > 0
ORDER BY tip_amount DESC
LIMIT 1000
おめでとうございます!
お疲れ様でした!チュートリアルを無事に完了し、ClickHouseの使い方についての理解が深まったことを願っています。次に何をするかのオプションはこちらです:
- ClickHouseの主キーの動作について読む - これはClickHouseのエキスパートになる旅に大いに役立ちます
- ファイル、Kafka、PostgreSQL、データパイプライン、その他多くのデータソースといった外部データソースを統合する
- お気に入りのUI/BIツールをClickHouseに接続する
- SQLリファレンスを確認し、さまざまな関数を参照すること。ClickHouseには、データの変換、処理、分析のための素晴らしいコレクションがあります
- Dictionariesについてさらに学ぶ