データモデリング手法
これは、PostgreSQLからClickHouseへの移行に関するガイドのパート3です。このコンテンツは入門的なものであり、ユーザーがClickHouseのベストプラクティスに準拠した初期の機能的なシステムを展開するのを助けることを目的としています。複雑なトピックを避け、完全に最適化されたスキーマにはなりませんが、本番システムを構築し、学習をベースにするための堅実な基盤を提供します。
Postgresから移行するユーザーには、ClickHouseでのデータモデリングに関するガイドを読むことをお勧めします。このガイドでは、同じStack Overflowデータセットを使用し、ClickHouseの機能を使用した複数のアプローチを探求します。
パーティション
Postgresユーザーは、大規模なデータベースのパフォーマンスと管理性を向上させるために、テーブルをより小さく管理しやすい部分に分割するテーブルパーティショニングの概念に慣れています。パーティショニングは、指定されたカラム(例:日付)の範囲、定義されたリスト、またはキーのハッシュを使用して達成されます。これにより、管理者は日付範囲や地理的な位置などの特定の基準に基づいてデータを整理することができます。パーティショニングは、パーティションプルーニングによるより高速なデータアクセスとより効率的なインデックス化を可能にすることでクエリのパフォーマンスを向上させます。また、バックアップやデータのパージのような保守作業を個々のパーティションで実行できるようにすることで効率を高めます。さらに、複数のパーティションに負荷を分散することで、PostgreSQLデータベースのスケーラビリティを大幅に向上させることができます。
ClickHouseでは、パーティショニングはテーブルが最初に定義される際にPARTITION BY句を通じて指定されます。この句には、任意のカラムに対するSQL式を含むことができ、その結果がどのパーティションに行を送るかを決定します。
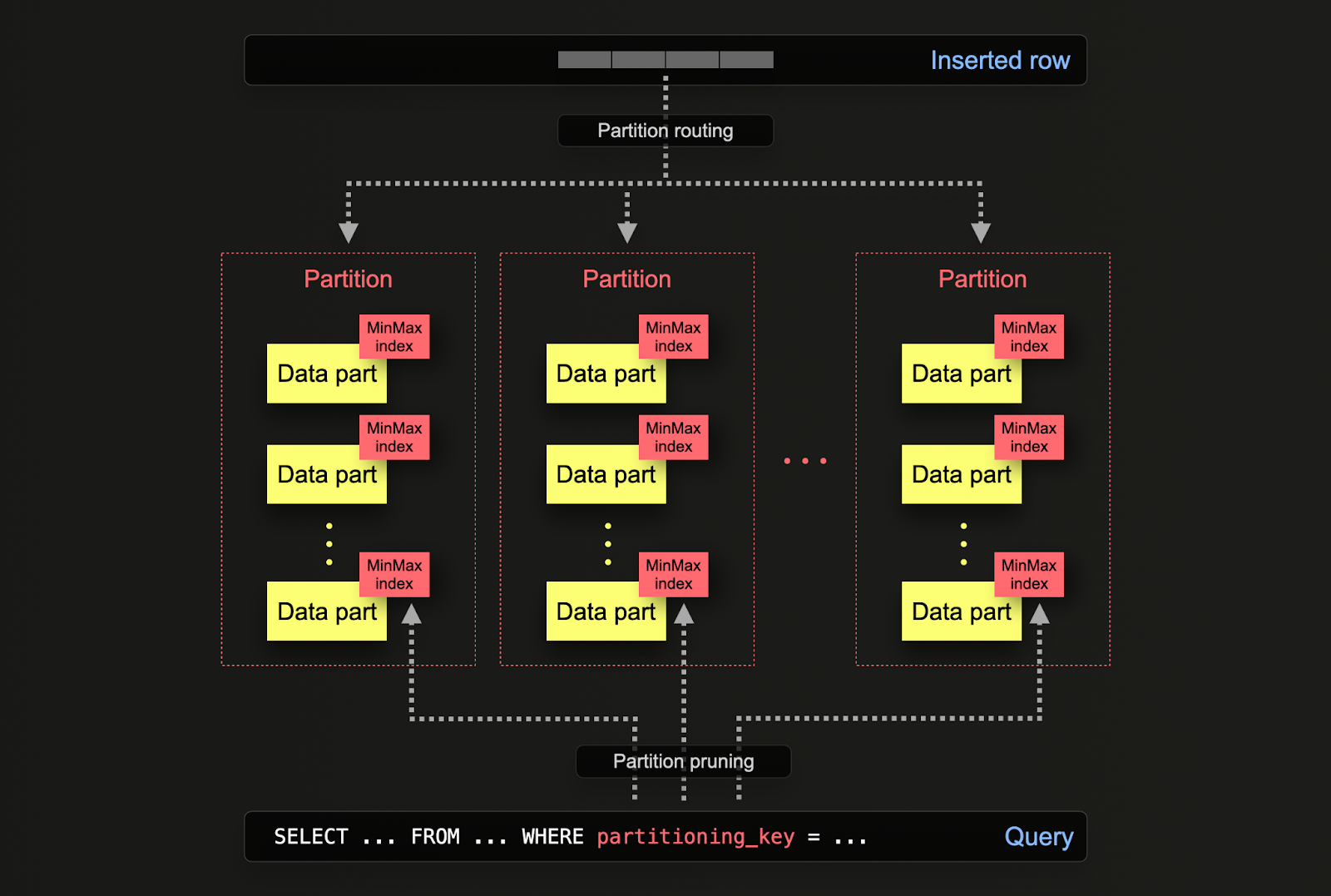
データパーツはディスク上で各パーティションに論理的に関連付けられ、個別にクエリを実行することができます。以下の例では、postsテーブルをtoYear(CreationDate)という式を使用して年ごとにパーティション分割します。行がClickHouseに挿入されると、この式が各行に対して評価され、該当するパーティションが存在する場合にルーティングされます(もし行がその年の最初のものであれば、パーティションが作成されます)。
CREATE TABLE posts
(
`Id` Int32 CODEC(Delta(4), ZSTD(1)),
`PostTypeId` Enum8('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
`AcceptedAnswerId` UInt32,
`CreationDate` DateTime64(3, 'UTC'),
...
`ClosedDate` DateTime64(3, 'UTC')
)
ENGINE = MergeTree
ORDER BY (PostTypeId, toDate(CreationDate), CreationDate)
PARTITION BY toYear(CreationDate)
パーティションの利用法
ClickHouseにおけるパーティショニングには、Postgresと同様の利用法がありますが、いくつか微妙な違いがあります。具体的には以下の通りです:
- データ管理 - ClickHouseでは、ユーザーは主にパーティショニングをデータ管理の機能と考えるべきであり、クエリの最適化技術とは考えないでください。キーに基づいてデータを論理的に分離することで、それぞれのパーティションを独立して操作することができます(例:削除)。これにより、パーティションを移動させることができるため、時間に応じて効率的にストレージ階層間でサブネットを移動させたり、データを期限切れにする/効率的にクラスターから削除することができます。例えば、以下では2008年の投稿を削除します。
SELECT DISTINCT partition
FROM system.parts
WHERE `table` = 'posts'
┌─partition─┐
│ 2008 │
│ 2009 │
│ 2010 │
│ 2011 │
│ 2012 │
│ 2013 │
│ 2014 │
│ 2015 │
│ 2016 │
│ 2017 │
│ 2018 │
│ 2019 │
│ 2020 │
│ 2021 │
│ 2022 │
│ 2023 │
│ 2024 │
└───────────┘
17 rows in set. Elapsed: 0.002 sec.
ALTER TABLE posts
(DROP PARTITION '2008')
Ok.
0 rows in set. Elapsed: 0.103 sec.
- クエリの最適化 - パーティションはクエリのパフォーマンスに役立つことがありますが、これはアクセスパターンに大きく依存します。クエリが数個(理想的には1つ)のパーティションのみをターゲットとする場合、性能が向上する可能性があります。これは通常、パーティショニングキーが主キーに含まれておらず、それでフィルタリングを行う場合に有用です。しかし、多くのパーティションをカバーする必要があるクエリは、パーティショニングを使用しない場合よりも性能が悪化する可能性があります(その結果、より多くのパーツが発生する可能性があるため)。特定のパーティションをターゲットとするメリットは、既に主キーの初期エントリとしてパーティショニングキーがある場合、存在しないかのように低下します。パーティショニングはまた、各パーティションの値がユニークである場合にGROUP BYクエリを最適化するためにも使用できます。しかし一般的に、ユーザーは主キーが最適化されていることを確認し、特定の予測可能なサブセットへのアクセスパターンがある例外的な場合にのみ、クエリ最適化技術としてパーティショニングを検討すべきです。例:日ごとにパーティショニングし、ほとんどのクエリが過去1日以内に行われる場合。
パーティションに関する推奨事項
ユーザーはパーティショニングをデータ管理の技術として考慮すべきです。これは、タイムシリーズデータを扱う際にクラスタからデータを期限切れにする必要がある場合に理想的です。例:最古のパーティションを単に削除することができます。
重要: パーティショニングキーの式が高カーディナリティのセットつまり100を超えるパーティションを生成しないことを確認してください。例えば、クライアント識別子や名前のような高カーディナリティのカラムでデータをパーティショニングしないでください。代わりに、クライアント識別子や名前をORDER BY式の最初のカラムにしてください。
内部的には、ClickHouseは挿入されたデータに対してパーツを生成します。データが多く挿入されるにつれて、パーツの数が増加します。クエリの性能を低下させる非常に多くのパーツを防ぐために、パーツはバックグラウンドの非同期プロセスで統合されます。パーツの数が設定された制限を超えると、ClickHouseは挿入時に例外をスローします。この問題は通常の操作下で発生せず、ClickHouseが誤って設定されているか誤って使用されている場合にのみ発生します。例:多くの小さな挿入。
パーツはパーティションごとに個別に作成されるため、パーティションの数が増えるとパーツの数も増えます。これはパーティション数の倍数です。したがって、高カーディナリティのパーティショニングキーはこのエラーを引き起こす可能性があるため、避けるべきです。
マテリアライズドビューとプロジェクション
Postgresでは、単一のテーブルに複数のインデックスを作成することで、さまざまなアクセスパターンを最適化できます。この柔軟性により、管理者と開発者は特定のクエリと運用ニーズに合わせてデータベースのパフォーマンスを調整することができます。ClickHouseのプロジェクションの概念はそれと完全に同一ではありませんが、テーブルに対して複数のORDER BY句を指定することができます。
ClickHouse データモデリングドキュメントでは、ClickHouseにおいてマテリアライズドビューがどのようにして集計を事前計算したり、行を変換したり、さまざまなアクセスパターンに基づいてクエリを最適化するために使用できるかを探求しています。
これに関連して、前述の例では、マテリアライズドビューが挿入を受ける元のテーブルとは別の順序キーで行をターゲットテーブルに送信する使い方を示しました。
例えば、次のクエリを考えてみてください:
SELECT avg(Score)
FROM comments
WHERE UserId = 8592047
┌──────────avg(Score)─┐
1. │ 0.18181818181818182 │
└─────────────────────┘
1 row in set. Elapsed: 0.040 sec. Processed 90.38 million rows, 361.59 MB (2.25 billion rows/s., 9.01 GB/s.)
Peak memory usage: 201.93 MiB.
このクエリはUserIdがオーダリングキーではないため、全90m行を(比較的高速に)スキャンする必要があります。以前は、PostIdのルックアップとして機能するマテリアライズドビューを使用してこの問題を解決しました。同じ問題はプロジェクションを使用して解決することができます。以下のコマンドはORDER BY user_idのプロジェクションを追加します。
ALTER TABLE comments ADD PROJECTION comments_user_id (
SELECT * ORDER BY UserId
)
ALTER TABLE comments MATERIALIZE PROJECTION comments_user_id
プロジェクションを最初に作成し、それをマテリアライズする必要があることに注意してください。この後者のコマンドは、データをディスク上に2回異なる順序で保持します。以下に示すように、データが作成される際にプロジェクションを定義することも可能であり、データが挿入されると自動的に維持されます。
CREATE TABLE comments
(
`Id` UInt32,
`PostId` UInt32,
`Score` UInt16,
`Text` String,
`CreationDate` DateTime64(3, 'UTC'),
`UserId` Int32,
`UserDisplayName` LowCardinality(String),
PROJECTION comments_user_id
(
SELECT *
ORDER BY UserId
)
)
ENGINE = MergeTree
ORDER BY PostId
ALTERでプロジェクションが作成される場合、MATERIALIZE PROJECTIONコマンドが発行されると、作成は非同期になります。ユーザーは以下のクエリを使用してこの操作の進行状況を確認し、is_done=1を待ちます。
SELECT
parts_to_do,
is_done,
latest_fail_reason
FROM system.mutations
WHERE (`table` = 'comments') AND (command LIKE '%MATERIALIZE%')
┌─parts_to_do─┬─is_done─┬─latest_fail_reason─┐
1. │ 1 │ 0 │ │
└─────────────┴─────────┴────────────────────┘
1 row in set. Elapsed: 0.003 sec.
上記のクエリを再実行すると、追加のストレージが必要となる代わりにパフォーマンスが大幅に改善されたことがわかります。
SELECT avg(Score)
FROM comments
WHERE UserId = 8592047
┌──────────avg(Score)─┐
1. │ 0.18181818181818182 │
└─────────────────────┘
1 row in set. Elapsed: 0.008 sec. Processed 16.36 thousand rows, 98.17 KB (2.15 million rows/s., 12.92 MB/s.)
Peak memory usage: 4.06 MiB.
EXPLAINコマンドを使用して、このクエリを供給するためにプロジェクションが使用されたことも確認できます:
EXPLAIN indexes = 1
SELECT avg(Score)
FROM comments
WHERE UserId = 8592047
┌─explain─────────────────────────────────────────────┐
1. │ Expression ((Projection + Before ORDER BY)) │
2. │ Aggregating │
3. │ Filter │
4. │ ReadFromMergeTree (comments_user_id) │
5. │ Indexes: │
6. │ PrimaryKey │
7. │ Keys: │
8. │ UserId │
9. │ Condition: (UserId in [8592047, 8592047]) │
10. │ Parts: 2/2 │
11. │ Granules: 2/11360 │
└─────────────────────────────────────────────────────┘
11 rows in set. Elapsed: 0.004 sec.
プロジェクションを使用するタイミング
プロジェクションは自動的にデータが挿入されると維持されるため、新しいユーザーには魅力的な機能です。さらに、クエリを単一のテーブルに送るだけで、それに応じてプロジェクションが活用され、応答時間が高速化されます。
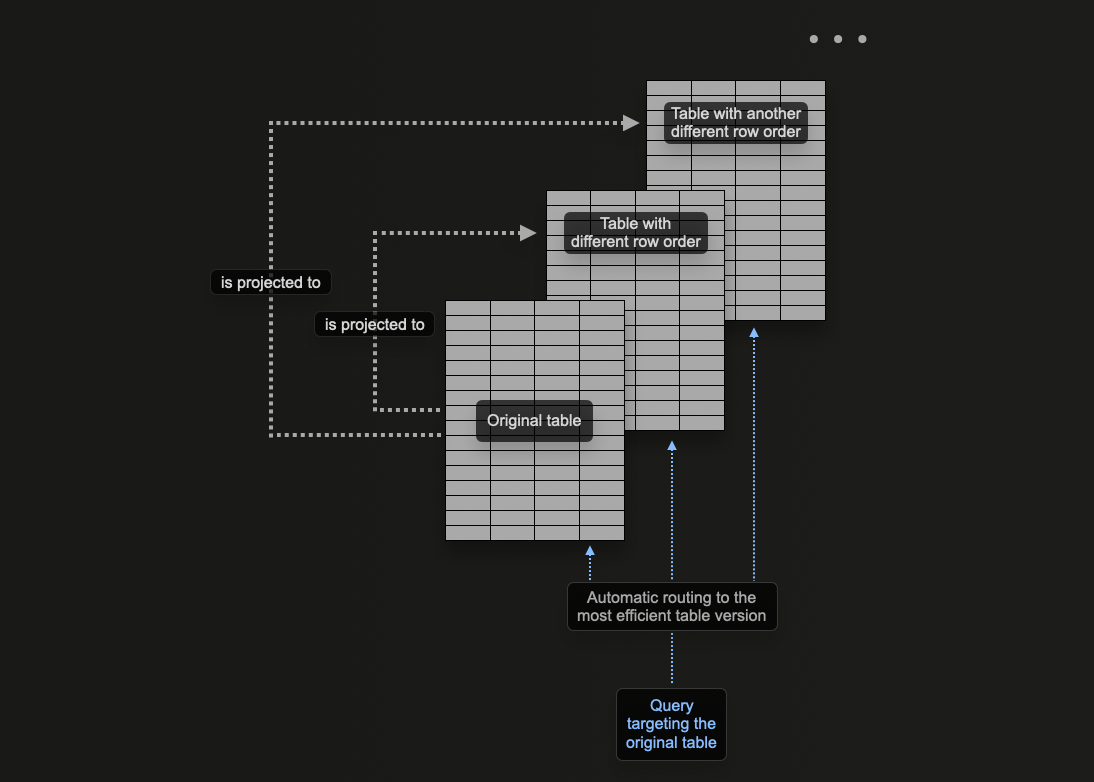
これはマテリアライズドビューと対照的であり、その場合、ユーザーはフィルタに応じて適切な最適化されたターゲットテーブルを選ぶか、クエリを書き換える必要があります。これはユーザーアプリケーションにより大きな重みを置き、クライアント側の複雑さを増します。
これらの利点にもかかわらず、プロジェクションには内部的な制限があり、ユーザーはそれを認識した上で、慎重に配備すべきです。
- プロジェクションは、ソーステーブルと(非表示の)ターゲットテーブルで異なるTTLを使用することはできませんが、マテリアライズドビューでは可能です。
- プロジェクションは、
optimize_read_in_orderを(非表示の)ターゲットテーブルで現時点ではサポートしていません。 - プロジェクションを持つテーブルでは軽量な更新や削除はサポートされていません。
- マテリアライズドビューは連鎖可能であり、あるマテリアライズドビューのターゲットテーブルを別のマテリアライズドビューのソーステーブルにすることができますが、プロジェクションではそれができません。
- プロジェクションはジョインをサポートしていませんが、マテリアライズドビューはサポートします。
- プロジェクションはフィルタ(WHERE句)をサポートしていませんが、マテリアライズドビューはサポートします。
プロジェクションを使用することをお勧めする状況は以下の場合です:
- データの完全な再順序が必要である場合。プロジェクションの中の式は理論的には
GROUP BYを使用できますが、集計を維持するにはマテリアライズドビューの方が効果的です。クエリオプティマイザーは、単純な再順序付け、すなわちSELECT * ORDER BY xを使用するプロジェクションをより多く利用しやすいです。これにより、ユーザーはこの式の中でカラムのサブセットを選んでストレージのフットプリントを減らすことができます。 - データを二重に書き込むことによるストレージフットプリントの増加に慣れています。挿入速度への影響をテストし、ストレージのオーバーヘッドを評価してください。