dbtとClickHouseの統合
dbt(データ構築ツール)は、分析エンジニアが倉庫内のデータを単純にSELECTステートメントを書くことで変換できるようにします。dbtは、これらのSELECTステートメントをデータベース内のテーブルやビューの形でオブジェクトにマテリアライズし、抽出・ロード・変換(ELT)のTを実行します。ユーザーはSELECTステートメントで定義されたモデルを作成できます。
dbt内では、これらのモデルは相互参照および重ね合わせが可能で、より高次の概念の構築を可能にします。モデルを接続するために必要な定型的なSQLは自動的に生成されます。さらに、dbtはモデル間の依存関係を特定し、有向非巡回グラフ(DAG)を使用して適切な順序で作成されることを保証します。
dbtは、ClickHouseがサポートするプラグインを通じてClickHouseと互換性があります。公に利用可能なIMDBデータセットに基づいた簡単な例を使用して、ClickHouseとの接続プロセスを説明します。また、現在のコネクタの限界もいくつか強調します。
概念
dbtは、モデルの概念を導入します。これは多くのテーブルを結合することもあるSQLステートメントとして定義されます。モデルは「マテリアライズ」する方法がいくつかあります。マテリアライズはモデルのSELECTクエリを構築するための戦略を表します。マテリアライズの背後にあるコードは、SELECTクエリをラップして新しく作成または既存のリレーションを更新するための定型的なSQLです。
dbtは4種類のマテリアライズを提供します:
- view(デフォルト): モデルがデータベース内でビューとして構築されます。
- table: モデルがデータベース内でテーブルとして構築されます。
- ephemeral: モデルは直接データベースに構築されませんが、共通テーブル式として依存モデルに引き込まれます。
- incremental: モデルは最初にテーブルとしてマテリアライズされ、その後の実行でdbtが新しい行を挿入し、テーブルの変更された行を更新します。
追加の構文と句は、モデルの基礎データが変わった場合にどのように更新すべきかを定義します。dbtは一般にパフォーマンスが問題になるまではviewマテリアライズをお勧めします。tableマテリアライズは、ストレージの増加の犠牲を払ってモデルのクエリの結果をテーブルとしてキャプチャすることでクエリ時間のパフォーマンス改善を提供します。incrementalアプローチは、基礎データに対する後続の更新をターゲットテーブルにキャプチャすることをさらに進めたものです。
現在のプラグインはClickHouseに対して、view、table, ephemeral およびincrementalマテリアライズをサポートしています。このプラグインは、dbtのスナップショットやシードもサポートしています。
以下のガイドでは、ClickHouseインスタンスが利用可能であることを前提とします。
dbtおよびClickHouseプラグインの設定
dbt
以下の例のためにdbt CLIの使用を前提とします。ユーザーはまた、webベースの統合開発環境(IDE)を提供するdbt Cloudを検討してもよいでしょう。
dbtはいくつかのCLIインストールオプションを提供します。こちらで説明されている指示に従ってください。この段階ではdbt-coreのみをインストールします。pipを使用することをお勧めします。
pip install dbt-core
重要: 以下はpython 3.9でテストされています。
ClickHouseプラグイン
dbt ClickHouseプラグインをインストールします:
pip install dbt-clickhouse
ClickHouseの準備
dbtは高い関連性を持つデータをモデリングするときに優れています。例の目的のために、次のリレーショナルスキーマを持つ小さなIMDBデータセットを提供します。このデータセットはリレーショナルデータセットリポジトリに由来します。これはdbtで使用される一般的なスキーマと比べて簡単なものでありますが、管理可能なサンプルを表しています。
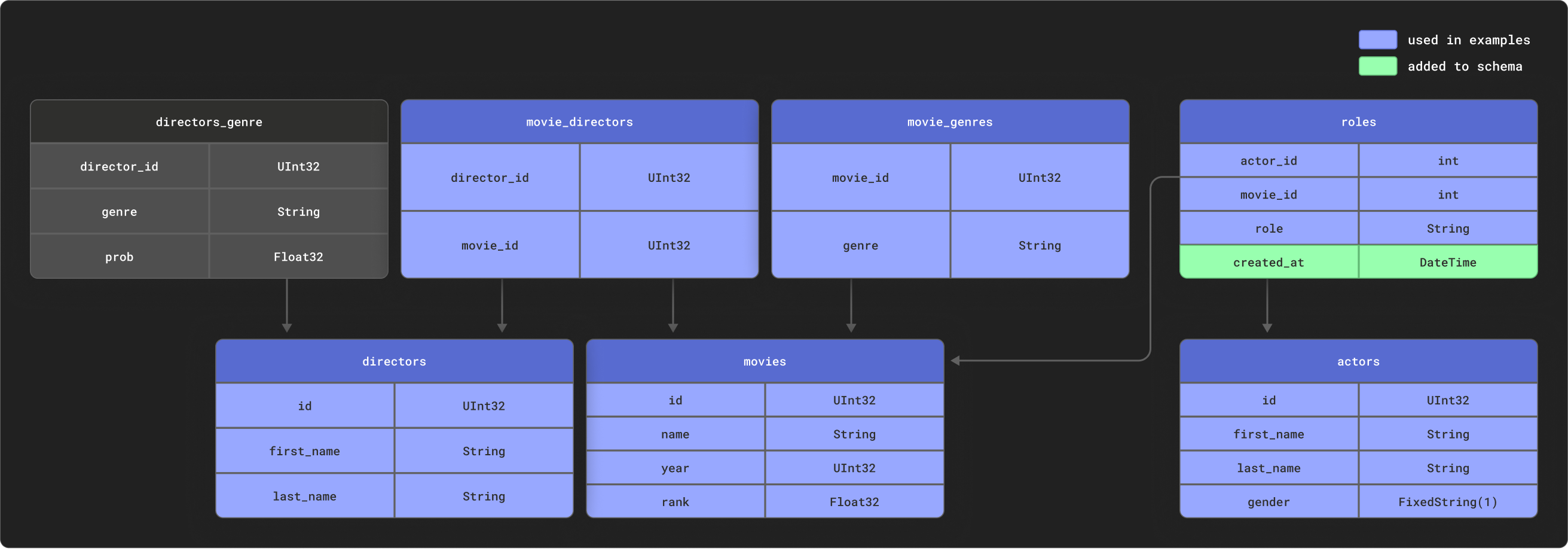
いくつかのテーブルをサブセットとして使用します。
以下のテーブルを作成します:
CREATE DATABASE imdb;
CREATE TABLE imdb.actors
(
id UInt32,
first_name String,
last_name String,
gender FixedString(1)
) ENGINE = MergeTree ORDER BY (id, first_name, last_name, gender);
CREATE TABLE imdb.directors
(
id UInt32,
first_name String,
last_name String
) ENGINE = MergeTree ORDER BY (id, first_name, last_name);
CREATE TABLE imdb.genres
(
movie_id UInt32,
genre String
) ENGINE = MergeTree ORDER BY (movie_id, genre);
CREATE TABLE imdb.movie_directors
(
director_id UInt32,
movie_id UInt64
) ENGINE = MergeTree ORDER BY (director_id, movie_id);
CREATE TABLE imdb.movies
(
id UInt32,
name String,
year UInt32,
rank Float32 DEFAULT 0
) ENGINE = MergeTree ORDER BY (id, name, year);
CREATE TABLE imdb.roles
(
actor_id UInt32,
movie_id UInt32,
role String,
created_at DateTime DEFAULT now()
) ENGINE = MergeTree ORDER BY (actor_id, movie_id);
テーブルrolesのカラムcreated_atは、デフォルトでnow()の値に設定されています。これは後でモデルのインクリメンタルな更新を識別するのに使用します - インクリメンタルマテリアライズの作成を参照してください。
s3関数を使用して公共のエンドポイントからソースデータを読み込みデータを挿入します。以下のコマンドを実行し、テーブルを埋めます:
INSERT INTO imdb.actors
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_actors.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.directors
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_directors.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.genres
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_movies_genres.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.movie_directors
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_movies_directors.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.movies
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_movies.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.roles(actor_id, movie_id, role)
SELECT actor_id, movie_id, role
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_roles.tsv.gz',
'TSVWithNames');
これらの実行時間は帯域幅によって異なるかもしれませんが、それぞれ数秒で完了するはずです。以下のクエリを実行し、映画出演回数の多い順にそれぞれの俳優の概要を計算し、データが正常にロードされたことを確認します:
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as unique_genres,
uniqExact(director_name) as uniq_directors,
max(created_at) as updated_at
FROM (
SELECT imdb.actors.id as id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) as actor_name,
imdb.movies.id as movie_id,
imdb.movies.rank as rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) as director_name,
created_at
FROM imdb.actors
JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT OUTER JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT OUTER JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
ORDER BY num_movies DESC
LIMIT 5;
応答は次のようになるはずです:
+------+------------+----------+------------------+-------------+--------------+-------------------+
|id |name |num_movies|avg_rank |unique_genres|uniq_directors|updated_at |
+------+------------+----------+------------------+-------------+--------------+-------------------+
|45332 |Mel Blanc |832 |6.175853582979779 |18 |84 |2022-04-26 14:01:45|
|621468|Bess Flowers|659 |5.57727638854796 |19 |293 |2022-04-26 14:01:46|
|372839|Lee Phelps |527 |5.032976449684617 |18 |261 |2022-04-26 14:01:46|
|283127|Tom London |525 |2.8721716524875673|17 |203 |2022-04-26 14:01:46|
|356804|Bud Osborne |515 |2.0389507108727773|15 |149 |2022-04-26 14:01:46|
+------+------------+----------+------------------+-------------+--------------+-------------------+
後のガイドでは、このクエリをモデルに変換し、ClickHouseにdbtビューやテーブルとしてマテリアライズします。
ClickHouseへの接続
dbtプロジェクトを作成します。この場合、imdbソースにちなんで名前を付けます。プロンプトが表示されたら、
clickhouseをデータベースソースとして選択します。clickhouse-user@clickhouse:~$ dbt init imdb
16:52:40 Running with dbt=1.1.0
Which database would you like to use?
[1] clickhouse
(Don't see the one you want? https://docs.getdbt.com/docs/available-adapters)
Enter a number: 1
16:53:21 No sample profile found for clickhouse.
16:53:21
Your new dbt project "imdb" was created!
For more information on how to configure the profiles.yml file,
please consult the dbt documentation here:
https://docs.getdbt.com/docs/configure-your-profilecdでプロジェクトフォルダに移動します:cd imdbこの時点で、お好みのテキストエディタを使用する必要があります。以下の例では、人気のあるVSCodeを使用します。IMDBディレクトリを開くと、ymlファイルとsqlファイルのコレクションが表示されます:
dbt_project.ymlファイルを更新して最初のモデル -actor_summaryを指定し、プロファイルをclickhouse_imdbに設定します。

次に、ClickHouseインスタンスへの接続情報をdbtに提供する必要があります。以下を
~/.dbt/profiles.ymlに追加します。clickhouse_imdb:
target: dev
outputs:
dev:
type: clickhouse
schema: imdb_dbt
host: localhost
port: 8123
user: default
password: ''
secure: Falseユーザーおよびパスワードの必要な変更に注意してください。利用可能な追加の設定はこちらでドキュメント化されています。
IMDBディレクトリから、
dbt debugコマンドを実行して、dbtがClickHouseに接続できるかどうかを確認します。clickhouse-user@clickhouse:~/imdb$ dbt debug
17:33:53 Running with dbt=1.1.0
dbt version: 1.1.0
python version: 3.10.1
python path: /home/dale/.pyenv/versions/3.10.1/bin/python3.10
os info: Linux-5.13.0-10039-tuxedo-x86_64-with-glibc2.31
Using profiles.yml file at /home/dale/.dbt/profiles.yml
Using dbt_project.yml file at /opt/dbt/imdb/dbt_project.yml
Configuration:
profiles.yml file [OK found and valid]
dbt_project.yml file [OK found and valid]
Required dependencies:
- git [OK found]
Connection:
host: localhost
port: 8123
user: default
schema: imdb_dbt
secure: False
verify: False
Connection test: [OK connection ok]
All checks passed!応答には
Connection test: [OK connection ok]が含まれていることを確認します。これは成功した接続を示しています。
シンプルなビューのマテリアライズの作成
viewマテリアライズを使用すると、モデルは各実行時にClickHouseのCREATE VIEW ASステートメントを介してビューとして再構築されます。これは、データの追加ストレージを必要としませんが、テーブルのマテリアライズよりもクエリが遅くなります。
imdbフォルダからmodels/exampleディレクトリを削除します:clickhouse-user@clickhouse:~/imdb$ rm -rf models/examplemodelsフォルダ内にactorsという名前の新しいファイルを作成します。ここで各俳優モデルを表すファイルを作成します:clickhouse-user@clickhouse:~/imdb$ mkdir models/actorsmodels/actorsフォルダにschema.ymlとactor_summary.sqlファイルを作成します。clickhouse-user@clickhouse:~/imdb$ touch models/actors/actor_summary.sql
clickhouse-user@clickhouse:~/imdb$ touch models/actors/schema.ymlファイル
schema.ymlはテーブルを定義します。これらはその後、マクロで使用できるようになります。models/actors/schema.ymlを次の内容に編集します:version: 2
sources:
- name: imdb
tables:
- name: directors
- name: actors
- name: roles
- name: movies
- name: genres
- name: movie_directorsactors_summary.sqlは実際のモデルを定義します。config関数でモデルがビューとしてClickHouseにマテリアライズされることを要求していることに注意してください。テーブルはschema.ymlファイルからsource関数を介して参照されます。例えば、source('imdb', 'movies')はimdbデータベースのmoviesテーブルを指します。models/actors/actors_summary.sqlを以下の内容に編集します:{{ config(materialized='view') }}
with actor_summary as (
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as genres,
uniqExact(director_name) as directors,
max(created_at) as updated_at
FROM (
SELECT {{ source('imdb', 'actors') }}.id as id,
concat({{ source('imdb', 'actors') }}.first_name, ' ', {{ source('imdb', 'actors') }}.last_name) as actor_name,
{{ source('imdb', 'movies') }}.id as movie_id,
{{ source('imdb', 'movies') }}.rank as rank,
genre,
concat({{ source('imdb', 'directors') }}.first_name, ' ', {{ source('imdb', 'directors') }}.last_name) as director_name,
created_at
FROM {{ source('imdb', 'actors') }}
JOIN {{ source('imdb', 'roles') }} ON {{ source('imdb', 'roles') }}.actor_id = {{ source('imdb', 'actors') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movies') }} ON {{ source('imdb', 'movies') }}.id = {{ source('imdb', 'roles') }}.movie_id
LEFT OUTER JOIN {{ source('imdb', 'genres') }} ON {{ source('imdb', 'genres') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movie_directors') }} ON {{ source('imdb', 'movie_directors') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'directors') }} ON {{ source('imdb', 'directors') }}.id = {{ source('imdb', 'movie_directors') }}.director_id
)
GROUP BY id
)
select *
from actor_summary最終的なactor_summaryにカラム
updated_atを含めることに注意してください。これを後でインクリメンタルなマテリアライズに使用します。imdbディレクトリから、dbt runコマンドを実行します。clickhouse-user@clickhouse:~/imdb$ dbt run
15:05:35 Running with dbt=1.1.0
15:05:35 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
15:05:35
15:05:36 Concurrency: 1 threads (target='dev')
15:05:36
15:05:36 1 of 1 START view model imdb_dbt.actor_summary.................................. [RUN]
15:05:37 1 of 1 OK created view model imdb_dbt.actor_summary............................. [OK in 1.00s]
15:05:37
15:05:37 Finished running 1 view model in 1.97s.
15:05:37
15:05:37 Completed successfully
15:05:37
15:05:37 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1dbtは要求に応じてモデルをClickHouseのビューとして表現します。これでこのビューを直接クエリできるようになります。このビューは
imdb_dbtデータベースに作成されているはずです - これは~/.dbt/profiles.ymlファイルのclickhouse_imdbプロファイルのschemaパラメーターで決定されます。SHOW DATABASES;+------------------+
|name |
+------------------+
|INFORMATION_SCHEMA|
|default |
|imdb |
|imdb_dbt | <---dbtによって作成されました!
|information_schema|
|system |
+------------------+このビューをクエリし、前のクエリの結果をよりシンプルな構文で再現できます:
SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 5;+------+------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+------------+----------+------------------+------+---------+-------------------+
|45332 |Mel Blanc |832 |6.175853582979779 |18 |84 |2022-04-26 15:26:55|
|621468|Bess Flowers|659 |5.57727638854796 |19 |293 |2022-04-26 15:26:57|
|372839|Lee Phelps |527 |5.032976449684617 |18 |261 |2022-04-26 15:26:56|
|283127|Tom London |525 |2.8721716524875673|17 |203 |2022-04-26 15:26:56|
|356804|Bud Osborne |515 |2.0389507108727773|15 |149 |2022-04-26 15:26:56|
+------+------------+----------+------------------+------+---------+-------------------+
テーブルのマテリアライズの作成
前の例では、モデルがビューとしてマテリアライズされました。これはいくつかのクエリには十分なパフォーマンスを提供するかもしれませんが、より複雑なSELECTが必要な場合や頻繁に実行されるクエリはテーブルとしてマテリアライズされた方が良いかもしれません。このマテリアライズは、BIツールによってクエリされる予定のモデルに対し、ユーザーがより速い体験を得られるようにするために有用です。これによりクエリ結果が新しいテーブルとして格納され、その結果ストレージのオーバーヘッドが増加します - これは事実上、INSERT TO SELECTが実行されます。このテーブルは毎回再構築されます:インクリメンタルではありません。そのため、大きな結果セットは長い実行時間につながる可能性があります - dbtの制限を参照してください。
ファイル
actors_summary.sqlを修正し、materializedパラメーターをtableに設定します。ORDER BYが定義されており、MergeTreeテーブルエンジンを使用していることに注意してください:{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='table') }}imdbディレクトリから、dbt runコマンドを実行します。実行は少し時間がかかるかもしれません - ほとんどのマシンで約10秒程度です。clickhouse-user@clickhouse:~/imdb$ dbt run
15:13:27 Running with dbt=1.1.0
15:13:27 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
15:13:27
15:13:28 Concurrency: 1 threads (target='dev')
15:13:28
15:13:28 1 of 1 START table model imdb_dbt.actor_summary................................. [RUN]
15:13:37 1 of 1 OK created table model imdb_dbt.actor_summary............................ [OK in 9.22s]
15:13:37
15:13:37 Finished running 1 table model in 10.20s.
15:13:37
15:13:37 Completed successfully
15:13:37
15:13:37 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1テーブル
imdb_dbt.actor_summaryの作成を確認します:SHOW CREATE TABLE imdb_dbt.actor_summary;適切なデータ型でテーブルを確認する必要があります:
+----------------------------------------
|statement
+----------------------------------------
|CREATE TABLE imdb_dbt.actor_summary
|(
|`id` UInt32,
|`first_name` String,
|`last_name` String,
|`num_movies` UInt64,
|`updated_at` DateTime
|)
|ENGINE = MergeTree
|ORDER BY (id, first_name, last_name)
|SETTINGS index_granularity = 8192
+----------------------------------------このテーブルからの結果が以前の応答と一貫していることを確認します。モデルがテーブルになったことで応答時間が著しく改善されたことに注目してください:
SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 5;+------+------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+------------+----------+------------------+------+---------+-------------------+
|45332 |Mel Blanc |832 |6.175853582979779 |18 |84 |2022-04-26 15:26:55|
|621468|Bess Flowers|659 |5.57727638854796 |19 |293 |2022-04-26 15:26:57|
|372839|Lee Phelps |527 |5.032976449684617 |18 |261 |2022-04-26 15:26:56|
|283127|Tom London |525 |2.8721716524875673|17 |203 |2022-04-26 15:26:56|
|356804|Bud Osborne |515 |2.0389507108727773|15 |149 |2022-04-26 15:26:56|
+------+------------+----------+------------------+------+---------+-------------------+このモデルに対する他のクエリを自由に発行してください。例えば、5回以上出演している俳優で最も高い評価を持つのは誰でしょうか?
SELECT * FROM imdb_dbt.actor_summary WHERE num_movies > 5 ORDER BY avg_rank DESC LIMIT 10;
インクリメンタルマテリアライズの作成
前の例では、モデルをマテリアライズするためにテーブルを作成しました。このテーブルはdbtの各実行で再構築されます。これは非現実的であり、結果セットが大きい場合や複雑な変換が行われる場合に非常にコストがかかる可能性があります。この課題に対処しビルド時間を短縮するために、dbtはインクリメンタルマテリアライズを提供しています。これは、dbtが前回の実行以降にテーブルに追加または更新されたレコードを挿入することを可能にし、イベントスタイルのデータに適しています。バックグラウンドでは、一時テーブルが作成されすべての更新されたレコードと未更新のレコードが新しい対象テーブルに挿入されます。この結果、テーブルモデルと同様に大きな結果セットに関する制限があります。
大きなセットの制限を克服するため、プラグインは「inserts_only」モードをサポートしています。このモードでは、すべての更新が一時テーブルを作成することなくターゲットテーブルに挿入されます(詳細は以下を参照)。
この例を示すために、Mel Blancよりも多くの映画に出演し、910本の映画に出演する俳優 "Clicky McClickHouse" を追加します。
まず、モデルをインクリメンタルタイプに変更します。この追加には以下が必要です:
- unique_key - プラグインが行を一意に識別できるようにするために、unique_keyを提供する必要があります。今回は、クエリの
idフィールドが適切です。これにより、マテリアライズされたテーブルに重複する行がないことを保証します。ユニーク性制約の詳細についてはこちらを参照してください。 - インクリメンタルフィルタ - また、dbtがインクリメンタル実行時に変更された行を識別する方法を教える必要があります。これはデルタ式を提供することで実現します。典型的にはイベントデータのタイムスタンプが関与します。したがって、
updated_atタイムスタンプフィールドを使用します。この列は、行が挿入されたときにnow()の値にデフォルト設定され、新しい役割を識別することができます。さらに、新しい俳優が追加された場合も識別する必要があります。既存のマテリアライズされたテーブルを示す{{this}}変数を使用し、以下のような式を得ることができます:where id > (select max(id) from {{ this }}) or updated_at > (select max(updated_at) from {{this}})。これは{% if is_incremental() %}条件内に埋め込み、インクリメンタル実行時にのみ使用されることを保証し、テーブルが最初に構築される際には使用されないことを確認します。インクリメンタルモデルの行フィルタリングの詳細については、dbtドキュメント内のこの議論を参照してください。
ファイル
actor_summary.sqlを次のように更新します:{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id') }}
with actor_summary as (
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as genres,
uniqExact(director_name) as directors,
max(created_at) as updated_at
FROM (
SELECT {{ source('imdb', 'actors') }}.id as id,
concat({{ source('imdb', 'actors') }}.first_name, ' ', {{ source('imdb', 'actors') }}.last_name) as actor_name,
{{ source('imdb', 'movies') }}.id as movie_id,
{{ source('imdb', 'movies') }}.rank as rank,
genre,
concat({{ source('imdb', 'directors') }}.first_name, ' ', {{ source('imdb', 'directors') }}.last_name) as director_name,
created_at
FROM {{ source('imdb', 'actors') }}
JOIN {{ source('imdb', 'roles') }} ON {{ source('imdb', 'roles') }}.actor_id = {{ source('imdb', 'actors') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movies') }} ON {{ source('imdb', 'movies') }}.id = {{ source('imdb', 'roles') }}.movie_id
LEFT OUTER JOIN {{ source('imdb', 'genres') }} ON {{ source('imdb', 'genres') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movie_directors') }} ON {{ source('imdb', 'movie_directors') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'directors') }} ON {{ source('imdb', 'directors') }}.id = {{ source('imdb', 'movie_directors') }}.director_id
)
GROUP BY id
)
select *
from actor_summary
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
where id > (select max(id) from {{ this }}) or updated_at > (select max(updated_at) from {{this}})
{% endif %}このモデルは、
rolesとactorsテーブルの更新と追加にのみ応答します。すべてのテーブルに応答するには、ユーザーがこのモデルを複数のサブモデルに分割することをお勧めします。 - それぞれ独自のインクリメンタル基準を持って。これらのモデルは順次参照および接続が可能です。モデルを相互参照する詳細についてはこちらを参照してください。- unique_key - プラグインが行を一意に識別できるようにするために、unique_keyを提供する必要があります。今回は、クエリの
dbt runを実行し、結果として得られるテーブルの結果を確認します:clickhouse-user@clickhouse:~/imdb$ dbt run
15:33:34 Running with dbt=1.1.0
15:33:34 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
15:33:34
15:33:35 Concurrency: 1 threads (target='dev')
15:33:35
15:33:35 1 of 1 START incremental model imdb_dbt.actor_summary........................... [RUN]
15:33:41 1 of 1 OK created incremental model imdb_dbt.actor_summary...................... [OK in 6.33s]
15:33:41
15:33:41 Finished running 1 incremental model in 7.30s.
15:33:41
15:33:41 Completed successfully
15:33:41
15:33:41 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 5;+------+------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+------------+----------+------------------+------+---------+-------------------+
|45332 |Mel Blanc |832 |6.175853582979779 |18 |84 |2022-04-26 15:26:55|
|621468|Bess Flowers|659 |5.57727638854796 |19 |293 |2022-04-26 15:26:57|
|372839|Lee Phelps |527 |5.032976449684617 |18 |261 |2022-04-26 15:26:56|
|283127|Tom London |525 |2.8721716524875673|17 |203 |2022-04-26 15:26:56|
|356804|Bud Osborne |515 |2.0389507108727773|15 |149 |2022-04-26 15:26:56|
+------+------------+----------+------------------+------+---------+-------------------+モデルにデータを追加してインクリメンタル更新を示します。新たに俳優"Clicky McClickHouse"を
actorsテーブルに追加します:INSERT INTO imdb.actors VALUES (845466, 'Clicky', 'McClickHouse', 'M');Clickyをランダムな910本の映画に出演させます:
INSERT INTO imdb.roles
SELECT now() as created_at, 845466 as actor_id, id as movie_id, 'Himself' as role
FROM imdb.movies
LIMIT 910 OFFSET 10000;基本となるソーステーブルをクエリしてdbtモデルをバイパスし、彼が本当に最も多く出演している俳優であることを確認します:
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as unique_genres,
uniqExact(director_name) as uniq_directors,
max(created_at) as updated_at
FROM (
SELECT imdb.actors.id as id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) as actor_name,
imdb.movies.id as movie_id,
imdb.movies.rank as rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) as director_name,
created_at
FROM imdb.actors
JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT OUTER JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT OUTER JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
ORDER BY num_movies DESC
LIMIT 2;+------+-------------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+-------------------+----------+------------------+------+---------+-------------------+
|845466|Clicky McClickHouse|910 |1.4687938697032283|21 |662 |2022-04-26 16:20:36|
|45332 |Mel Blanc |909 |5.7884792542982515|19 |148 |2022-04-26 16:17:42|
+------+-------------------+----------+------------------+------+---------+-------------------+dbt runを実行し、モデルが更新され、上記の結果と一致することを確認します:clickhouse-user@clickhouse:~/imdb$ dbt run
16:12:16 Running with dbt=1.1.0
16:12:16 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
16:12:16
16:12:17 Concurrency: 1 threads (target='dev')
16:12:17
16:12:17 1 of 1 START incremental model imdb_dbt.actor_summary........................... [RUN]
16:12:24 1 of 1 OK created incremental model imdb_dbt.actor_summary...................... [OK in 6.82s]
16:12:24
16:12:24 Finished running 1 incremental model in 7.79s.
16:12:24
16:12:24 Completed successfully
16:12:24
16:12:24 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 2;+------+-------------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+-------------------+----------+------------------+------+---------+-------------------+
|845466|Clicky McClickHouse|910 |1.4687938697032283|21 |662 |2022-04-26 16:20:36|
|45332 |Mel Blanc |909 |5.7884792542982515|19 |148 |2022-04-26 16:17:42|
+------+-------------------+----------+------------------+------+---------+-------------------+
内部
上記のインクリメンタル更新を達成するために実行されたステートメントをClickHouseのクエリログをクエリして特定できます。
SELECT event_time, query FROM system.query_log WHERE type='QueryStart' AND query LIKE '%dbt%'
AND event_time > subtractMinutes(now(), 15) ORDER BY event_time LIMIT 100;
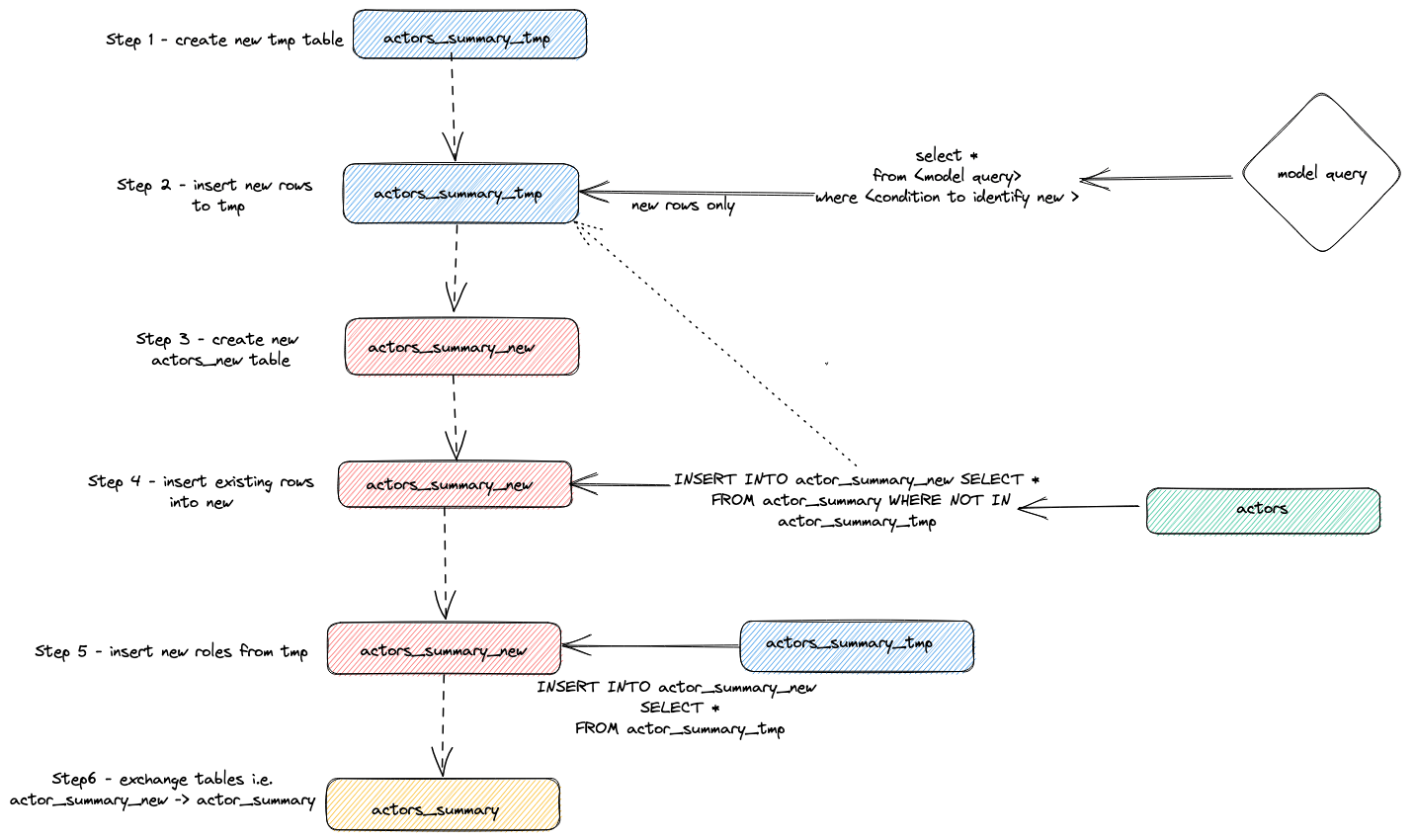
上記のクエリを実行時間に合わせて調整します。結果の検査はユーザーに委ねますが、プラグインがインクリメンタル更新を実行するために使用する一般的な戦略を強調します:
- プラグインは一時テーブル
actor_sumary__dbt_tmpを作成します。変更された行がこのテーブルにストリーミングされます。 - 新しいテーブル
actor_summary_newが作成されます。古いテーブルから行が、新しいテーブルにストリーミングされ、一時テーブルに存在しない行idを確認します。これにより、更新と重複が効果的に処理されます。 - 一時テーブルからの結果が新しい
actor_summaryテーブルにストリーミングされます。 - 最後に、
EXCHANGE TABLESステートメントを介して古いバージョンと新しいテーブルが原子的に交換されます。古いテーブルと一時テーブルは開放されます。
これは以下に視覚化されています:
この戦略は非常に大きなモデルで課題に遭遇する可能性があります。さらなる詳細についてはLimitationsを参照してください。
アペンドストラテジー(inserts_onlyモード)
インクリメンタルモデルの大規模なデータセットの制限を克服するために、プラグインはdbt構成パラメーターincremental_strategyを使用します。これは値appendに設定することができます。このモードが設定されると、更新行は一時テーブルを作成することなく直接ターゲットテーブルに挿入されます。
注意:アペンドオンリーモードはデータが不変であることを前提としており、重複が許容される必要があります。変更された行をサポートするインクリメンタルテーブルモデルを使用したい場合は、このモードを使用しないでください!
このモードを例証するために、さらに新しい俳優を追加し、incremental_strategy='append'でdbt runを再実行します。
filesactor_summary.sql内でappend onlyモードを設定します:
{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id', incremental_strategy='append') }}もう一人の有名な俳優 - Danny DeBitoを追加します
INSERT INTO imdb.actors VALUES (845467, 'Danny', 'DeBito', 'M');Dannyをランダムな920本の映画に主演させます。
INSERT INTO imdb.roles
SELECT now() as created_at, 845467 as actor_id, id as movie_id, 'Himself' as role
FROM imdb.movies
LIMIT 920 OFFSET 10000;dbt runを実行し、Dannyがactor-summaryテーブルに追加されたことを確認します。
clickhouse-user@clickhouse:~/imdb$ dbt run
16:12:16 Running with dbt=1.1.0
16:12:16 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 186 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
16:12:16
16:12:17 Concurrency: 1 threads (target='dev')
16:12:17
16:12:17 1 of 1 START incremental model imdb_dbt.actor_summary........................... [RUN]
16:12:24 1 of 1 OK created incremental model imdb_dbt.actor_summary...................... [OK in 0.17s]
16:12:24
16:12:24 Finished running 1 incremental model in 0.19s.
16:12:24
16:12:24 Completed successfully
16:12:24
16:12:24 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 3;+------+-------------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+-------------------+----------+------------------+------+---------+-------------------+
|845467|Danny DeBito |920 |1.4768987303293204|21 |670 |2022-04-26 16:22:06|
|845466|Clicky McClickHouse|910 |1.4687938697032283|21 |662 |2022-04-26 16:20:36|
|45332 |Mel Blanc |909 |5.7884792542982515|19 |148 |2022-04-26 16:17:42|
+------+-------------------+----------+------------------+------+---------+-------------------+
このインクリメンタルがClickyの挿入時よりもどれだけ速かったかに注意してください。
再度のquery_logテーブルの確認で、2つのインクリメンタル実行の違いが明らかになります:
insert into imdb_dbt.actor_summary ("id", "name", "num_movies", "avg_rank", "genres", "directors", "updated_at")
with actor_summary as (
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as genres,
uniqExact(director_name) as directors,
max(created_at) as updated_at
FROM (
SELECT imdb.actors.id as id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) as actor_name,
imdb.movies.id as movie_id,
imdb.movies.rank as rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) as director_name,
created_at
FROM imdb.actors
JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT OUTER JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT OUTER JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
)
select *
from actor_summary
-- this filter will only be applied on an incremental run
where id > (select max(id) from imdb_dbt.actor_summary) or updated_at > (select max(updated_at) from imdb_dbt.actor_summary)
この実行では、新しい行のみが直接imdb_dbt.actor_summaryテーブルに追加され、テーブルの作成は行われません。
Delete+Insertモード (エクスペリメンタル)
歴史的にClickHouseは、非同期のミューテーションとして、更新および削除に対して限定的なサポートしか提供してきませんでした。これは非常にIO負荷が大きく、通常は避けるべきです。
ClickHouse 22.8では論理削除が導入されました。これらは現在エクスペリメンタルであるが、データ削除をよりパフォーマントに行う手段を提供します。
このモードはモデルのincremental_strategyパラメーターで構成できます。例えば:
{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id', incremental_strategy='delete+insert') }}
この戦略はターゲットモデルのテーブルを直接操作するため、操作中に問題が発生した場合、インクリメンタルモデル内のデータが無効な状態になる可能性があります - 原子的な更新はありません。
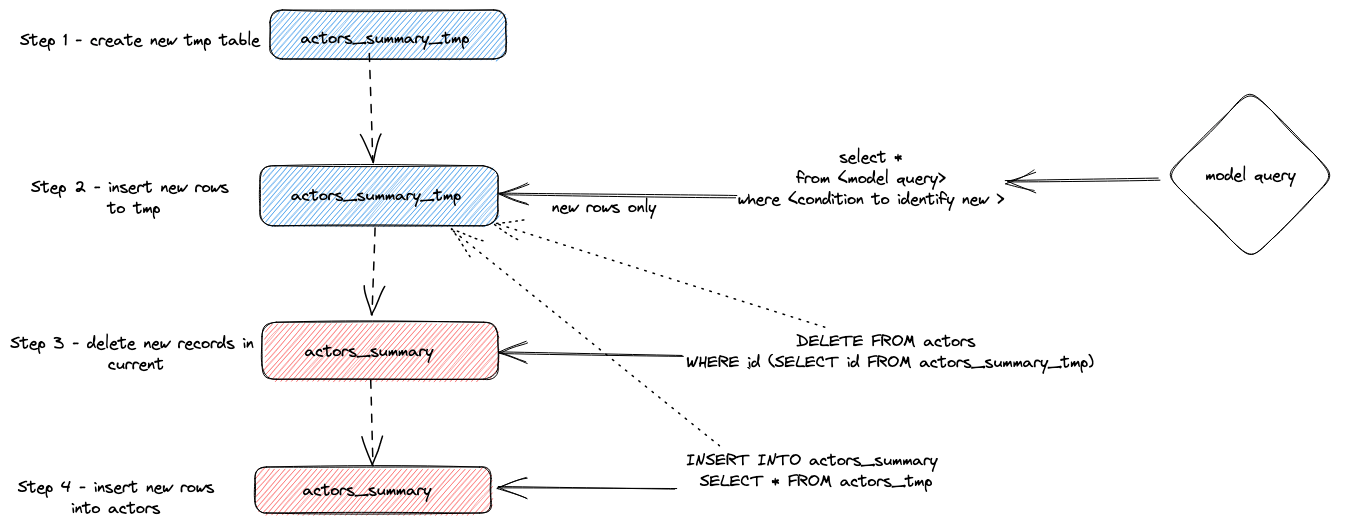
要約すると、このアプローチは次のように機能します:
- プラグインは一時テーブル
actor_sumary__dbt_tmpを作成します。変更された行がこのテーブルにストリーミングされます。 - 現在の
actor_summaryテーブルに対してDELETEが発行されます。行はactor_sumary__dbt_tmpからidで削除されます。 actor_sumary__dbt_tmpからの行はINSERT INTO actor_summary SELECT * FROM actor_sumary__dbt_tmpを使用してactor_summaryに挿入されます。
このプロセスは以下に示されています:
insert_overwriteモード(エクスペリメンタル)
次の手順を実行します:
- インクリメンタルモデルリレーションと同じ構造を持つステージング(一時)テーブルを作成します:CREATE TABLE {staging} AS {target}。
- 新しいレコード(SELECTによって生成された)をステージングテーブルにのみ挿入します。
- 新しいパーティション(ステージングテーブルに存在する)のみをターゲットテーブルに置き換えます。
このアプローチには以下の利点があります:
- テーブル全体をコピーしないため、デフォルトの戦略よりも高速です。
- 中間障害の際には元のテーブルが変更されないため、他の戦略よりも安全です:操作が成功裏に完了するまで、元のテーブルは変更されません。
- 「パーティション不変性」データ工学ベストプラクティスを実装します。これによりインクリメンタルかつ並列なデータ処理、ロールバックなどが簡単になります。
insert_overwrite機能はまだマルチノード設定でテストされていません。
この機能の実装に関する詳細情報は、導入したPRをご覧ください。
スナップショットの作成
dbtスナップショットにより、時間経過とともに可変モデルの変更を記録することができます。これにより、アナリストがモデルの以前の状態を「時間をさかのぼって」確認できる時間点のクエリが可能になります。これはタイプ2緩やかな変更次元を使用して実現され、行が有効であった場合、fromおよびtoの日付列が記録されます。この機能はClickHouseプラグインでサポートされており、以下でデモンストレーションを行います。
この例は、Creating an Incremental Table Modelを完了したことを前提としています。ここで、actor_summary.sqlがinserts_only=Trueを設定していないことを確認してください。あなたのmodels/actor_summary.sqlは次のようになっているはずです:
{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id') }}
with actor_summary as (
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as genres,
uniqExact(director_name) as directors,
max(created_at) as updated_at
FROM (
SELECT {{ source('imdb', 'actors') }}.id as id,
concat({{ source('imdb', 'actors') }}.first_name, ' ', {{ source('imdb', 'actors') }}.last_name) as actor_name,
{{ source('imdb', 'movies') }}.id as movie_id,
{{ source('imdb', 'movies') }}.rank as rank,
genre,
concat({{ source('imdb', 'directors') }}.first_name, ' ', {{ source('imdb', 'directors') }}.last_name) as director_name,
created_at
FROM {{ source('imdb', 'actors') }}
JOIN {{ source('imdb', 'roles') }} ON {{ source('imdb', 'roles') }}.actor_id = {{ source('imdb', 'actors') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movies') }} ON {{ source('imdb', 'movies') }}.id = {{ source('imdb', 'roles') }}.movie_id
LEFT OUTER JOIN {{ source('imdb', 'genres') }} ON {{ source('imdb', 'genres') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movie_directors') }} ON {{ source('imdb', 'movie_directors') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'directors') }} ON {{ source('imdb', 'directors') }}.id = {{ source('imdb', 'movie_directors') }}.director_id
)
GROUP BY id
)
select *
from actor_summary
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
where id > (select max(id) from {{ this }}) or updated_at > (select max(updated_at) from {{this}})
{% endif %}
スナップショットディレクトリ内に
actor_summaryファイルを作成します。touch snapshots/actor_summary.sqlactor_summary.sqlファイルの内容を以下のように更新します:
{% snapshot actor_summary_snapshot %}
{{
config(
target_schema='snapshots',
unique_key='id',
strategy='timestamp',
updated_at='updated_at',
)
}}
select * from {{ref('actor_summary')}}
{% endsnapshot %}
この内容に関するいくつかの留意点:
- selectクエリは時間経過にわたりスナップショットを取得したい結果を定義します。関数refを使用して、以前に作成したactor_summaryモデルを参照しています。
- 我々はレコードの変更を示すタイムスタンプ列が必要です。我々のupdated_at列(Creating an Incremental Table Modelを参照)がここで使用できます。パラメータstrategyは更新を示すタイムスタンプの使用を示しており、パラメータupdated_atは使用する列を指定しています。これがモデルに存在しない場合、check strategyを代わりに使用できます。これははるかに非効率的であり、ユーザーが比較する列のリストを指定する必要があります。dbtはこれらの列の現在値と履歴値を比較し、変更がある場合はそれらを記録します(全く同じ場合は何もしません)。
dbt snapshotコマンドを実行します。clickhouse-user@clickhouse:~/imdb$ dbt snapshot
13:26:23 Running with dbt=1.1.0
13:26:23 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 3 sources, 0 exposures, 0 metrics
13:26:23
13:26:25 Concurrency: 1 threads (target='dev')
13:26:25
13:26:25 1 of 1 START snapshot snapshots.actor_summary_snapshot...................... [RUN]
13:26:25 1 of 1 OK snapshotted snapshots.actor_summary_snapshot...................... [OK in 0.79s]
13:26:25
13:26:25 Finished running 1 snapshot in 2.11s.
13:26:25
13:26:25 Completed successfully
13:26:25
13:26:25 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
noteとして、actor_summary_snapshotというテーブルがsnapshots dbに作成されていることに注意してください(target_schemaパラメータで決定されます)。
このデータをサンプリングすると、dbtがカラムdbt_valid_fromおよびdbt_valid_toを含めた方法がわかります。後者の値はnullに設定されています。その後の実行でこれが更新されます。
SELECT id, name, num_movies, dbt_valid_from, dbt_valid_to FROM snapshots.actor_summary_snapshot ORDER BY num_movies DESC LIMIT 5;+------+----------+------------+----------+-------------------+------------+
|id |first_name|last_name |num_movies|dbt_valid_from |dbt_valid_to|
+------+----------+------------+----------+-------------------+------------+
|845467|Danny |DeBito |920 |2022-05-25 19:33:32|NULL |
|845466|Clicky |McClickHouse|910 |2022-05-25 19:32:34|NULL |
|45332 |Mel |Blanc |909 |2022-05-25 19:31:47|NULL |
|621468|Bess |Flowers |672 |2022-05-25 19:31:47|NULL |
|283127|Tom |London |549 |2022-05-25 19:31:47|NULL |
+------+----------+------------+----------+-------------------+------------+お気に入りの俳優Clicky McClickHouseをもう10本の映画に出演させます。
INSERT INTO imdb.roles
SELECT now() as created_at, 845466 as actor_id, rand(number) % 412320 as movie_id, 'Himself' as role
FROM system.numbers
LIMIT 10;imdbディレクトリからdbt runコマンドを再実行します。これによりインクリメンタルモデルが更新されます。これが完了したら、dbt snapshotを実行して変更をキャプチャします。
clickhouse-user@clickhouse:~/imdb$ dbt run
13:46:14 Running with dbt=1.1.0
13:46:14 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 3 sources, 0 exposures, 0 metrics
13:46:14
13:46:15 Concurrency: 1 threads (target='dev')
13:46:15
13:46:15 1 of 1 START incremental model imdb_dbt.actor_summary....................... [RUN]
13:46:18 1 of 1 OK created incremental model imdb_dbt.actor_summary.................. [OK in 2.76s]
13:46:18
13:46:18 Finished running 1 incremental model in 3.73s.
13:46:18
13:46:18 Completed successfully
13:46:18
13:46:18 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
clickhouse-user@clickhouse:~/imdb$ dbt snapshot
13:46:26 Running with dbt=1.1.0
13:46:26 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 3 sources, 0 exposures, 0 metrics
13:46:26
13:46:27 Concurrency: 1 threads (target='dev')
13:46:27
13:46:27 1 of 1 START snapshot snapshots.actor_summary_snapshot...................... [RUN]
13:46:31 1 of 1 OK snapshotted snapshots.actor_summary_snapshot...................... [OK in 4.05s]
13:46:31
13:46:31 Finished running 1 snapshot in 5.02s.
13:46:31
13:46:31 Completed successfully
13:46:31
13:46:31 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1スナップショットをクエリするとき、Clicky McClickHouse の行が2つあることに注意してください。以前のエントリは現在
dbt_valid_toの値を持っています。新しい値はdbt_valid_fromカラムに同じ値で記録され、dbt_valid_toの値は null です。新しい行があれば、それらもスナップショットに追加されます。SELECT id, name, num_movies, dbt_valid_from, dbt_valid_to FROM snapshots.actor_summary_snapshot ORDER BY num_movies DESC LIMIT 5;+------+----------+------------+----------+-------------------+-------------------+
|id |first_name|last_name |num_movies|dbt_valid_from |dbt_valid_to |
+------+----------+------------+----------+-------------------+-------------------+
|845467|Danny |DeBito |920 |2022-05-25 19:33:32|NULL |
|845466|Clicky |McClickHouse|920 |2022-05-25 19:34:37|NULL |
|845466|Clicky |McClickHouse|910 |2022-05-25 19:32:34|2022-05-25 19:34:37|
|45332 |Mel |Blanc |909 |2022-05-25 19:31:47|NULL |
|621468|Bess |Flowers |672 |2022-05-25 19:31:47|NULL |
+------+----------+------------+----------+-------------------+-------------------+
dbtスナップショットの詳細についてはこちらを参照してください。
Seedの使用
dbt は CSV ファイルからデータをロードする機能を提供します。この機能はデータベースの大規模なエクスポートをロードするためのものではなく、通常はコードテーブルやDictionaryで使用される小さなファイル向けに設計されています。簡単な例として、ジャンルコードのリストを生成してから、seed機能を使用してアップロードします。
既存のデータセットからジャンルコードのリストを生成します。dbtディレクトリから、
clickhouse-clientを使用してseeds/genre_codes.csvというファイルを作成します:clickhouse-user@clickhouse:~/imdb$ clickhouse-client --password <password> --query
"SELECT genre, ucase(substring(genre, 1, 3)) as code FROM imdb.genres GROUP BY genre
LIMIT 100 FORMAT CSVWithNames" > seeds/genre_codes.csvdbt seedコマンドを実行します。これにより、CSVファイルの行を持つ新しいテーブルgenre_codesがデータベースimdb_dbtに作成されます(スキーマ設定で定義されたとおり)。clickhouse-user@clickhouse:~/imdb$ dbt seed
17:03:23 Running with dbt=1.1.0
17:03:23 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 1 seed file, 6 sources, 0 exposures, 0 metrics
17:03:23
17:03:24 Concurrency: 1 threads (target='dev')
17:03:24
17:03:24 1 of 1 START seed file imdb_dbt.genre_codes..................................... [RUN]
17:03:24 1 of 1 OK loaded seed file imdb_dbt.genre_codes................................. [INSERT 21 in 0.65s]
17:03:24
17:03:24 Finished running 1 seed in 1.62s.
17:03:24
17:03:24 Completed successfully
17:03:24
17:03:24 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1以下のように確認してください:
SELECT * FROM imdb_dbt.genre_codes LIMIT 10;+-------+----+
|genre |code|
+-------+----+
|Drama |DRA |
|Romance|ROM |
|Short |SHO |
|Mystery|MYS |
|Adult |ADU |
|Family |FAM |
|Action |ACT |
|Sci-Fi |SCI |
|Horror |HOR |
|War |WAR |
+-------+----+
制限事項
現在のdbt用ClickHouseプラグインにはいくつかの制限事項があります。ユーザーは以下の点に注意してください:
- プラグインは現在、
INSERT TO SELECTを使用してモデルをテーブルとしてマテリアライズします。これは事実上、データの重複を意味します。非常に大規模なデータセット(PB)は非常に長い実行時間を生じさせる可能性があり、一部のモデルが利用できなくなります。クエリで返される行数を最小限に抑え、可能であればGROUP BYを使用してください。ソースの行数を維持する単なる変換よりもデータを要約するモデルを好んで使用してください。 - モデルを表すために分散テーブルを使用するには、ユーザーは各ノードに基盤となるレプリケートされたテーブルを手動で作成する必要があります。その上に分散テーブルを作成することができます。プラグインはクラスタの作成を管理しません。
- dbtがデータベースに関係(テーブル/ビュー)を作成する際、通常は
{{ database }}.{{ schema }}.{{ table/view id }}として作成します。ClickHouseにはスキーマの概念がありません。そのため、プラグインは{{schema}}.{{ table/view id }}を使用します。ここでschemaは ClickHouse のデータベースです。
詳細情報
これまでのガイドはdbtの機能の表面に触れただけです。ユーザーは素晴らしいdbtのドキュメントを読むことをお勧めします。
プラグインの追加設定についてはこちらを参照してください。
関連コンテンツ
- ブログ & ウェビナー: ClickHouse and dbt - A Gift from the Community