ClickHouse Cloud クイックスタート
ClickHouse をすぐにセットアップして利用を開始する最速かつ最も簡単な方法は、ClickHouse Cloudで新しいサービスを作成することです。
1: ClickHouse を入手する
ClickHouse Cloudで無料の ClickHouse サービスを作成するには、次のステップを完了するだけでサインアップできます:
- サインアップページでアカウントを作成
- 受信したメール内のリンクをクリックしてメールアドレスを確認
- 作成したユーザー名とパスワードでログイン
ログインすると、ClickHouse Cloud のオンボーディングウィザードが開始され、新しい ClickHouse サービスの作成をガイドしてくれます。サービスの展開先のリージョンを選択し、新しいサービスに名前を付けます:
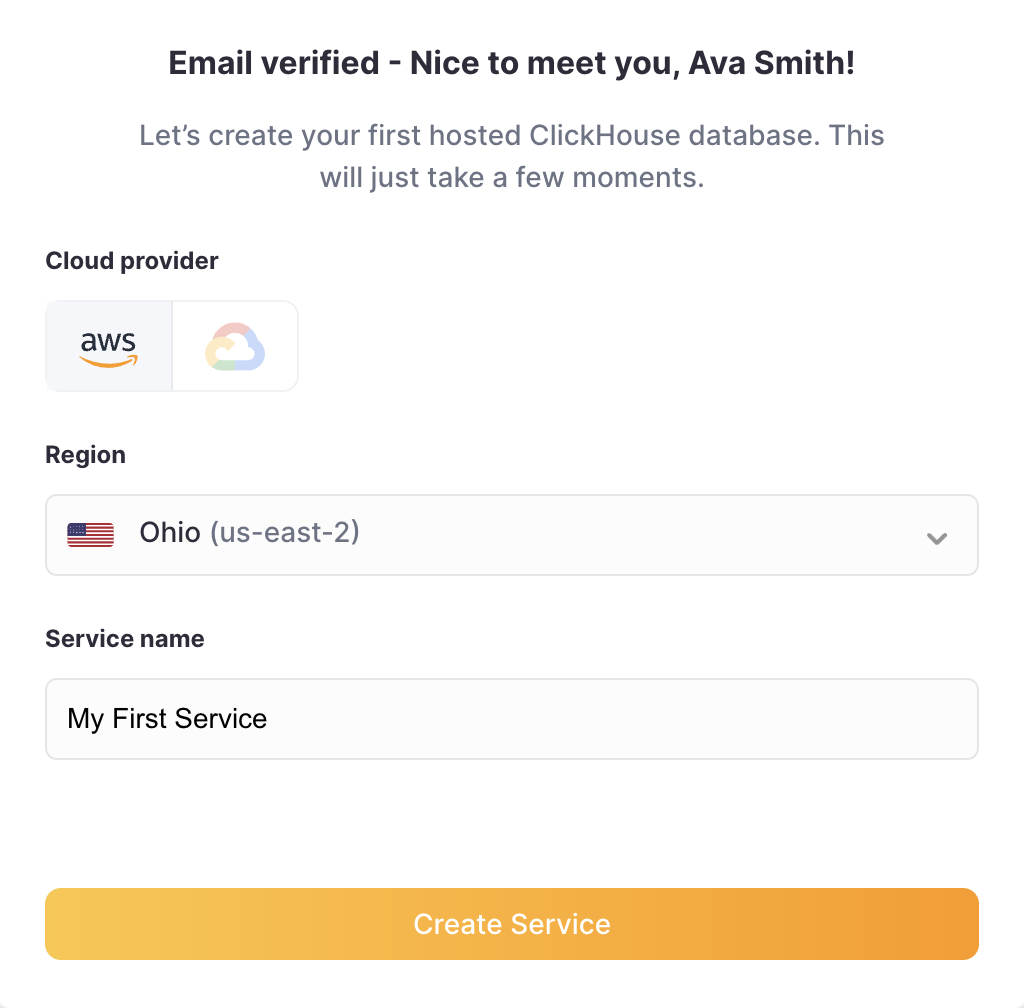
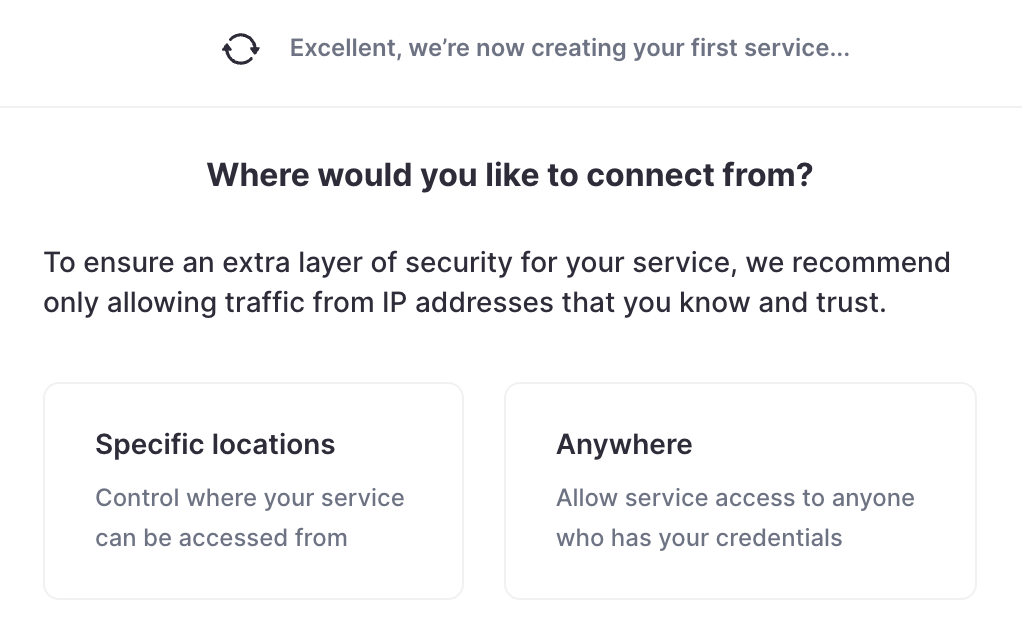
ClickHouse Cloud は IP フィルタリングを使用してサービスへのアクセスを制限します。ローカル IP アドレスが既に追加されていることに注意してください。サービスが起動してから追加することもできます。
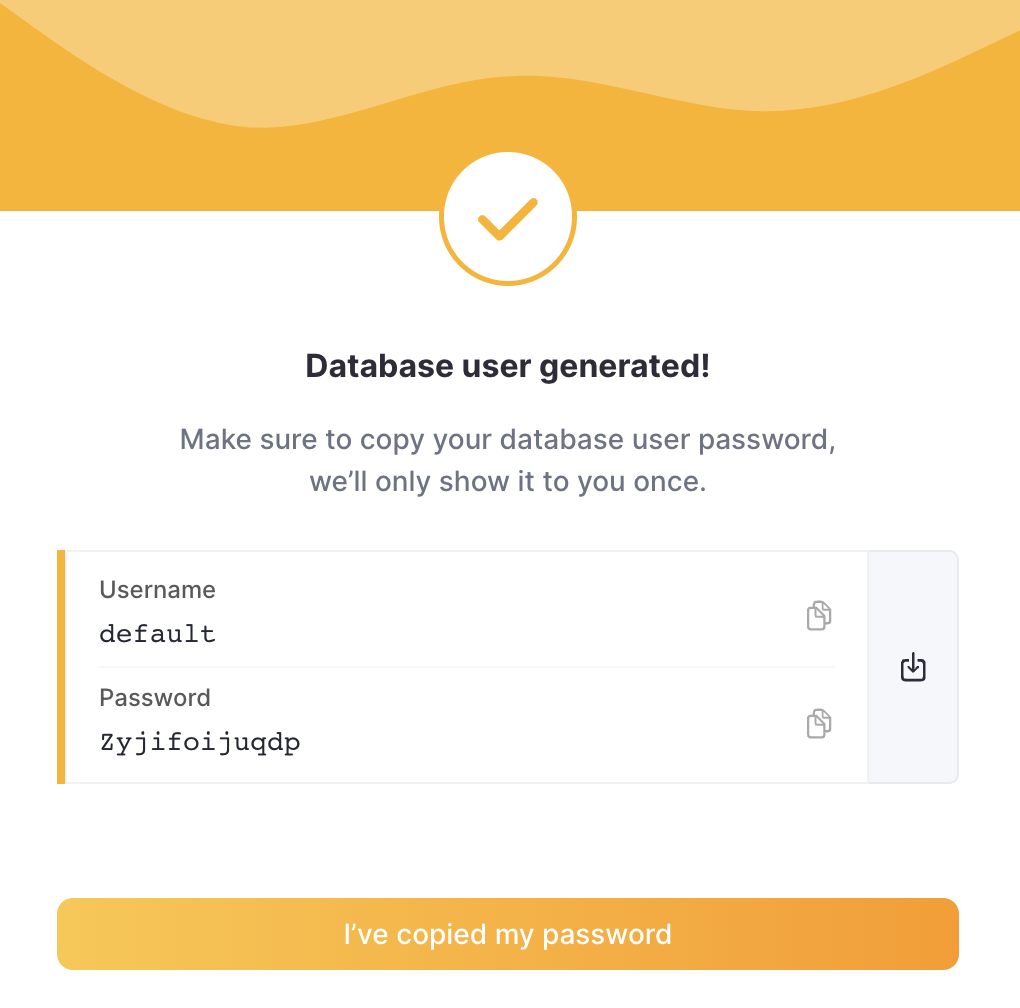
ClickHouse Cloud は default ユーザーのためにパスワードを生成します。資格情報を必ず保存してください。(後で変更可能です。)
新しいサービスがプロビジョニングされ、ClickHouse Cloud ダッシュボードに表示されるはずです:
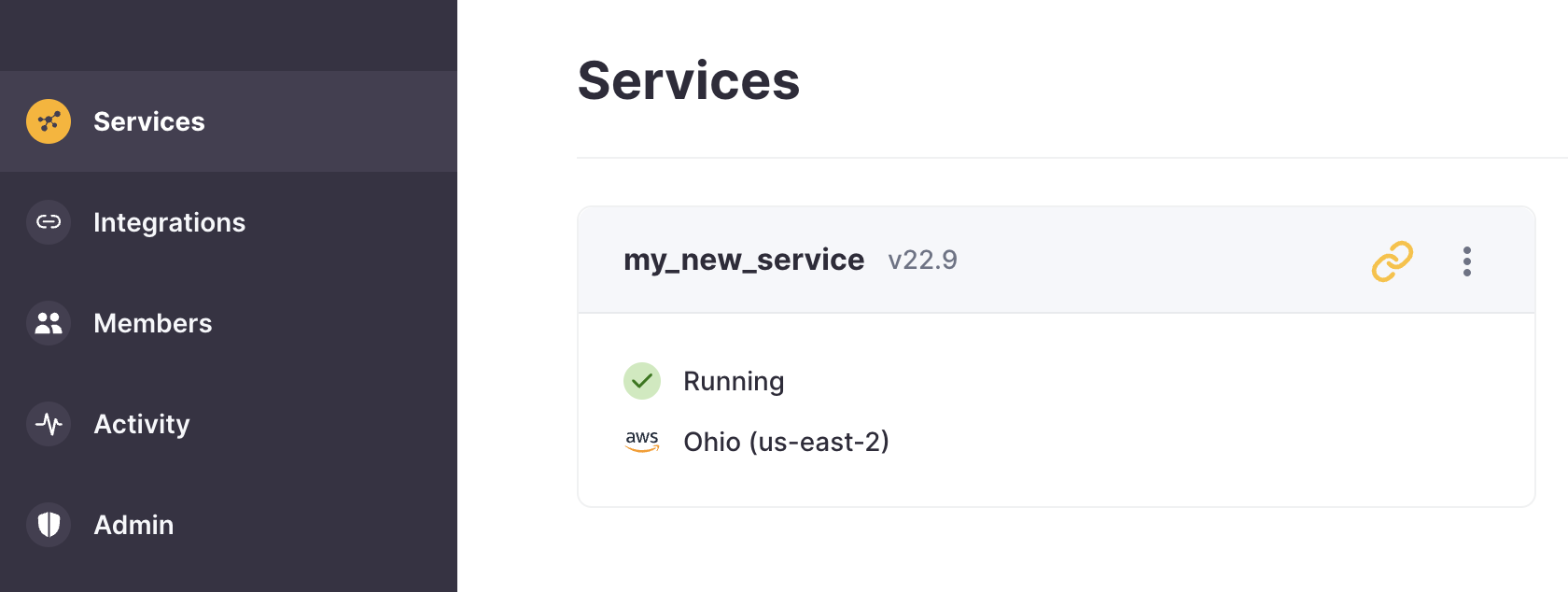
おめでとうございます!ClickHouse Cloud サービスが起動しました。接続方法やデータのインジェストを開始する方法について、引き続きお読みください。
2: ClickHouse に接続
素早く始めるために、ClickHouse ではウェブベースの SQL コンソールが提供されています。
SQL クライアント接続が必要な場合、ClickHouse Cloud サービスには関連付けられたウェブベースの SQL コンソールがあります。詳細については、以下の SQL コンソールに接続 を展開してください。
SQL コンソールに接続
ClickHouse Cloud サービス一覧から、作業するサービスを選択し、接続 をクリックします。ここから SQL コンソールを開く ことができます:
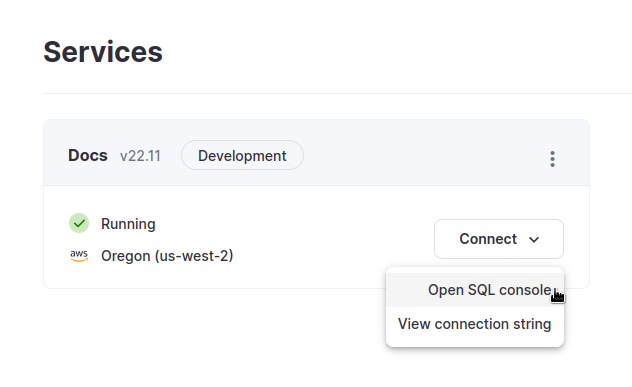
ClickHouse はデータのセキュリティを非常に重視しているため、サービス作成時に IP アクセスリストの設定が求められました。これをスキップしたり誤って閉じたりした場合、サービスに接続できません。
ローカル IP アドレスの追加方法については、IP アクセスリストのドキュメントページを参照してください。
接続が正常に動作するか確認するために、簡単なクエリを入力しましょう:
SHOW databasesリストには 4 つのデータベースが表示され、追加したものがあればそれも含まれます。
これで、新しい ClickHouse サービスを使用する準備が整いました!
3: データベースとテーブルを作成
ほとんどのデータベース管理システムと同様に、ClickHouse はテーブルを論理的にデータベースにグループ化します。新しいデータベースを ClickHouse に作成するには
CREATE DATABASEコマンドを使用します:CREATE DATABASE IF NOT EXISTS helloworldhelloworldデータベースにmy_first_tableという名前のテーブルを作成するには次のコマンドを実行します:CREATE TABLE helloworld.my_first_table
(
user_id UInt32,
message String,
timestamp DateTime,
metric Float32
)
ENGINE = MergeTree()
PRIMARY KEY (user_id, timestamp)上記の例では、
my_first_tableは4つのカラムを持つ MergeTree テーブルです:user_id: 32ビットの符号なし整数message: 他のデータベースシステムでの VARCHAR, BLOB, CLOB などに置き換わる String データ型timestamp: 時間を表す DateTime 値metric: 32ビットの浮動小数点数
テーブルエンジンテーブルエンジンは以下を決定します:
- データがどのように、どこに保存されるか
- どのクエリがサポートされるか
- データがレプリケーションされるかどうか
選択可能なエンジンは多数ありますが、単一ノードの ClickHouse サーバー上のシンプルなテーブルには MergeTree が一般的な選択です。
主キーの簡単な紹介
先に進む前に、ClickHouse における主キーの働きについて理解することが重要です(主キーの実装が予想外に思えるかもしれません!):
- ClickHouse の主キーはテーブルの各行に対して一意ではありません
ClickHouse テーブルの主キーはデータがディスクに書き込まれる際の並び順を決定します。8,192 行または 10MB のデータごとに(インデックス粒度として参照される)主キーインデックスファイルにエントリが作成されます。この粒度の概念により、スパースインデックスがメモリに簡単に適合し、粒度は
SELECTクエリ処理時に処理される最小のカラムデータのストライプを表します。主キーは
PRIMARY KEYパラメータを使用して定義できます。PRIMARY KEYを指定しないでテーブルを定義すると、キーはORDER BY句に指定されたタプルになります。PRIMARY KEYとORDER BYの両方を指定した場合、主キーはソート順のサブセットでなければなりません。主キーはまたソートキーであり
(user_id, timestamp)のタプルです。したがって、各カラムファイルに格納されるデータはuser_id、次にtimestampの順にソートされます。
4: データを挿入
ClickHouse ではおなじみの INSERT INTO TABLE コマンドを使用できますが、MergeTree テーブルへの各挿入がストレージにパートを作成することを理解することが重要です。
バッチごとに大量(数万または数百万)の行を挿入してください。心配いりません - ClickHouse はそうしたボリュームを容易に処理でき、それが コスト削減 にも繋がります。
簡単な例であっても、複数の行を同時に挿入しましょう:
INSERT INTO helloworld.my_first_table (user_id, message, timestamp, metric) VALUES
(101, 'Hello, ClickHouse!', now(), -1.0 ),
(102, 'Insert a lot of rows per batch', yesterday(), 1.41421 ),
(102, 'Sort your data based on your commonly-used queries', today(), 2.718 ),
(101, 'Granules are the smallest chunks of data read', now() + 5, 3.14159 )Notetimestampカラムがさまざまな Date および DateTime 関数を使用して埋められていることに注意してください。ClickHouse には多くの便利な関数があります。詳細は関数セクションを参照してください。挿入が成功したか確認しましょう:
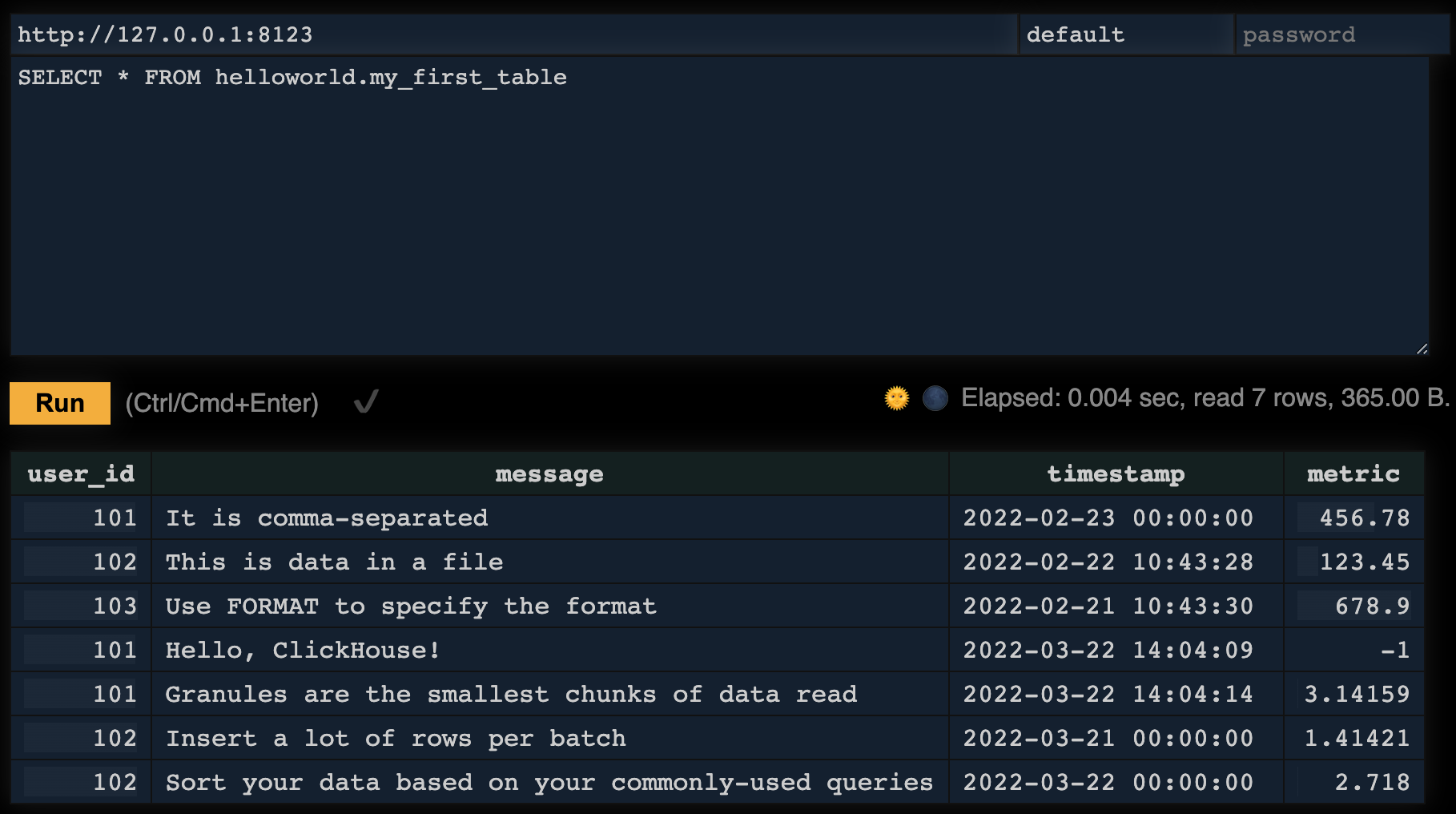
SELECT * FROM helloworld.my_first_table挿入された4つの行が表示されるはずです:
5: ClickHouse クライアントを使用する
コマンドラインツール clickhouse client を使用して ClickHouse Cloud サービスに接続することもできます。接続詳細はサービスの Native タブに記載されています:
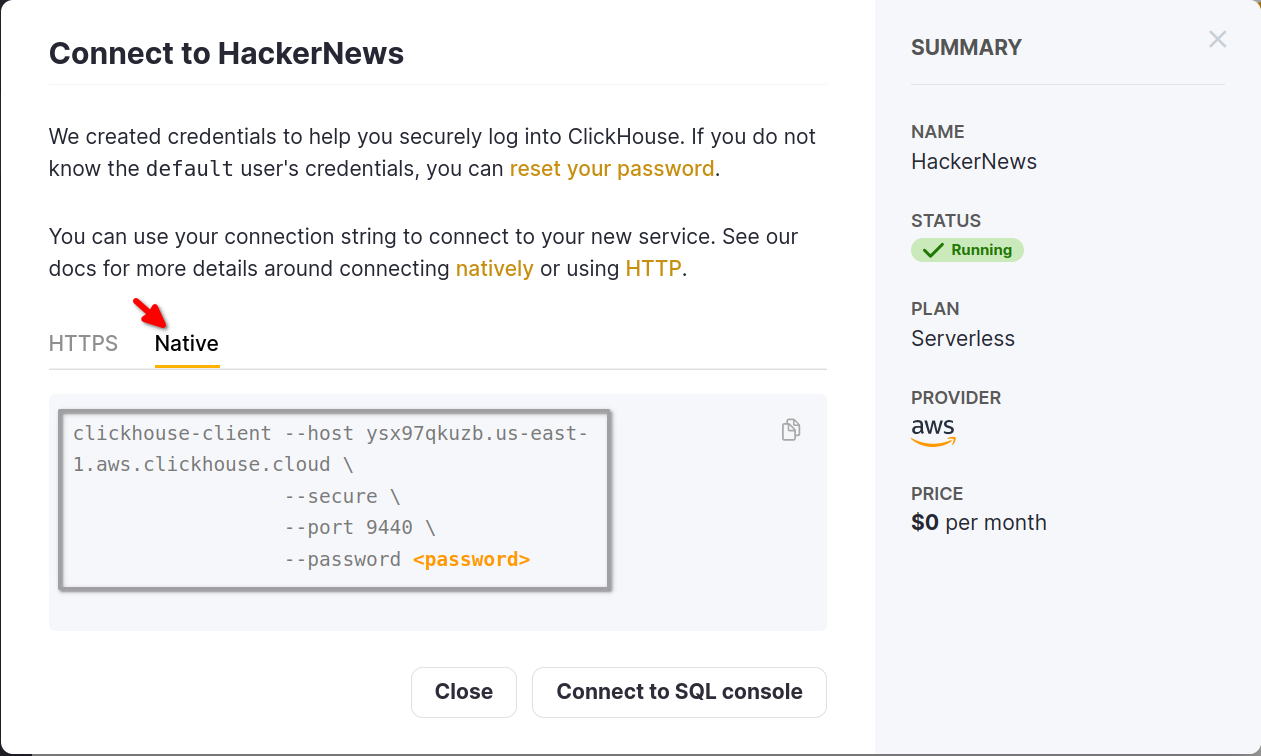
ClickHouse をインストールします。
ホスト名、ユーザー名、パスワードを差し替えてコマンドを実行します:
./clickhouse client --host HOSTNAME.REGION.CSP.clickhouse.cloud \
--secure --port 9440 \
--user default \
--password <password>スマイリーフェイスのプロンプトが表示されたら、クエリを実行する準備が整いました!
:)次のクエリを実行してみましょう:
SELECT *
FROM helloworld.my_first_table
ORDER BY timestamp応答が整ったテーブル形式で返ってくることに注目してください:
┌─user_id─┬─message────────────────────────────────────────────┬───────────timestamp─┬──metric─┐
│ 102 │ Insert a lot of rows per batch │ 2022-03-21 00:00:00 │ 1.41421 │
│ 102 │ Sort your data based on your commonly-used queries │ 2022-03-22 00:00:00 │ 2.718 │
│ 101 │ Hello, ClickHouse! │ 2022-03-22 14:04:09 │ -1 │
│ 101 │ Granules are the smallest chunks of data read │ 2022-03-22 14:04:14 │ 3.14159 │
└─────────┴────────────────────────────────────────────────────┴─────────────────────┴─────────┘
4 rows in set. Elapsed: 0.008 sec.FORMAT句を追加してその一つを指定すべき ClickHouse の多くのサポートされている出力形式 のいずれかを指定してください:SELECT *
FROM helloworld.my_first_table
ORDER BY timestamp
FORMAT TabSeparated上記のクエリでは、出力はタブ区切りで返されます:
Query id: 3604df1c-acfd-4117-9c56-f86c69721121
102 Insert a lot of rows per batch 2022-03-21 00:00:00 1.41421
102 Sort your data based on your commonly-used queries 2022-03-22 00:00:00 2.718
101 Hello, ClickHouse! 2022-03-22 14:04:09 -1
101 Granules are the smallest chunks of data read 2022-03-22 14:04:14 3.14159
4 rows in set. Elapsed: 0.005 sec.clickhouse clientを終了するには、exit コマンドを入力します:exit
6: CSV ファイルを挿入する
データベースを始める際に一般的なタスクは、既にファイルにあるデータを挿入することです。ユーザーID、訪問した URL、イベントのタイムスタンプを含むクリックストリームデータを表すサンプルデータをオンラインで提供しています。
data.csv という名前の CSV ファイルに次のテキストがあるとします:
102,This is data in a file,2022-02-22 10:43:28,123.45
101,It is comma-separated,2022-02-23 00:00:00,456.78
103,Use FORMAT to specify the format,2022-02-21 10:43:30,678.90
次のコマンドは
my_first_tableにデータを挿入します:./clickhouse client --host HOSTNAME.REGION.CSP.clickhouse.cloud \
--secure --port 9440 \
--user default \
--password <password> \
--query='INSERT INTO helloworld.my_first_table FORMAT CSV' < data.csvテーブルに新しい行が表示されることに注目してください:
次は何をすべきか?
- チュートリアル では200万行のデータをテーブルに挿入し、分析クエリを書く体験を提供します
- 例データセット のリストと、それらを挿入する手順があります
- ClickHouse の始め方に関する25分のビデオをご覧ください
- 外部ソースからデータを取得する場合、メッセージキュー、データベース、パイプラインなどとの接続方法についての統合ガイドのコレクションを参照してください
- UI/BI 可視化ツールを使用している場合、UI を ClickHouse に接続するためのユーザーガイド を参照してください
- 主キーに関するすべてのことを知るためには、主キーに関するユーザーガイドを参照してください