障害耐性のためのレプリケーション
説明
このアーキテクチャでは、5台のサーバーが構成されています。2台はデータのコピーをホストするために使われます。残りの3台のサーバーはデータのレプリケーションを調整するために使われます。この例では、ReplicatedMergeTreeテーブルエンジンを使用して、両方のデータノードにわたってレプリケートされるデータベースとテーブルを作成します。
レベル: 基本
用語集
レプリカ
データのコピー。ClickHouseは常にデータの少なくとも1つのコピーを持っているため、レプリカの最小数は1です。これは重要なポイントで、元のデータをレプリカとして数えることに慣れていないかもしれませんが、ClickHouseのコードとドキュメントではその用語が使用されています。データの2番目のレプリカを追加することで、フォールトトレランスを提供できます。
シャード
データのサブセット。ClickHouseは常にデータの少なくとも1つのシャードを持っているので、データを複数のサーバーに分散しない場合、データは1つのシャードに格納されます。データを複数のサーバーに分散してシャーディングすることは、単一サーバーの容量を超えた場合に負荷を分散するために利用できます。宛先サーバーはシャーディングキーによって決まり、分散テーブルを作成する際に定義されます。シャーディングキーはランダムなものか、ハッシュ関数の出力として定義することができます。シャーディングを含むデプロイメント例では、シャーディングキーとしてrand()を使用し、いつどのようにして異なるシャーディングキーを選択するかについてのさらなる情報を提供します。
分散調整
ClickHouse Keeperは、データのレプリケーションと分散DDLクエリの実行のための調整システムを提供します。ClickHouse KeeperはApache ZooKeeperと互換性があります。
環境
アーキテクチャ図
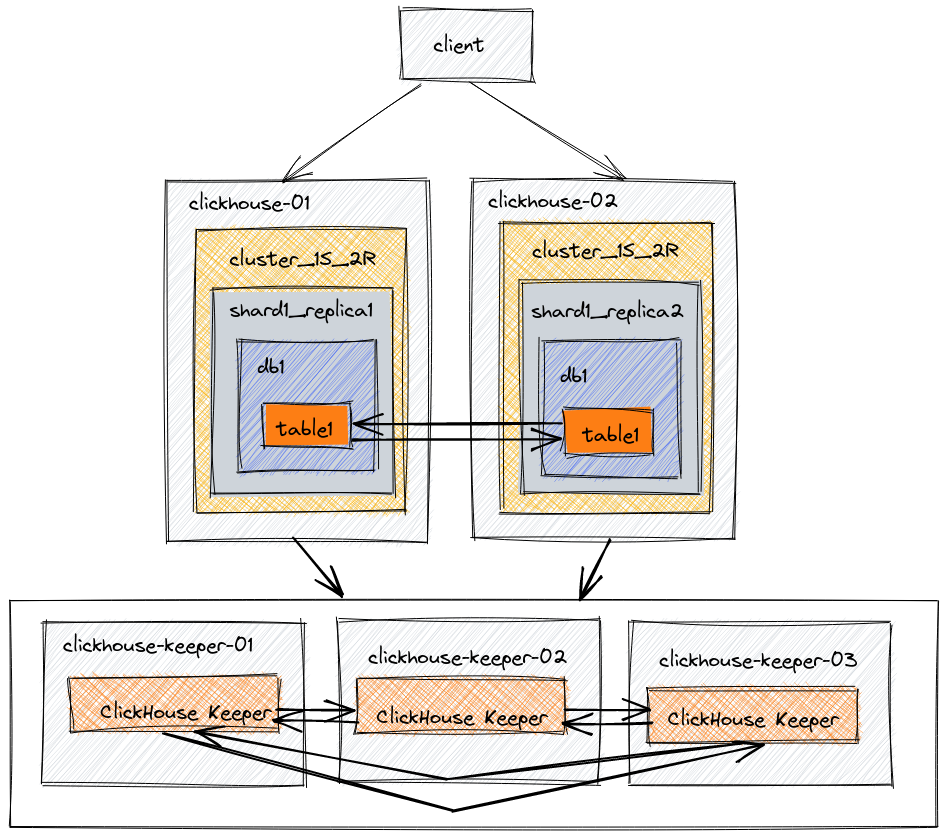
| Node | 説明 |
|---|---|
| clickhouse-01 | データ |
| clickhouse-02 | データ |
| clickhouse-keeper-01 | 分散コーディネーション |
| clickhouse-keeper-02 | 分散コーディネーション |
| clickhouse-keeper-03 | 分散コーディネーション |
本番環境では、ClickHouse Keeperのために専用のホストを使用することを強くお勧めします。テスト環境では、ClickHouse ServerとClickHouse Keeperを同じサーバー上で組み合わせて実行することが許容されます。他の基本的な例、スケールアウトでは、この方法を使用しています。この例では、KeeperとClickHouse Serverを分離する推奨される方法を示します。Keeperサーバーは小さくすることができ、ClickHouse Serversが非常に大きくなるまで、各Keeperサーバーには通常4GB RAMがあれば十分です。
インストール
2台のサーバーclickhouse-01とclickhouse-02にClickHouse serverとclientをインストールします。アーカイブタイプに応じた手順 (.deb, .rpm, .tar.gzなど)に従ってください。
3台のサーバーclickhouse-keeper-01、clickhouse-keeper-02、clickhouse-keeper-03にClickHouse Keeperをインストールします。アーカイブタイプに応じた手順に従ってください (.deb, .rpm, .tar.gzなど)。
設定ファイルの編集
ClickHouse Server を設定する際、設定ファイルを追加または編集するときは次のようにしてください:
- ファイルを
/etc/clickhouse-server/config.d/ディレクトリに追加する - ファイルを
/etc/clickhouse-server/users.d/ディレクトリに追加する /etc/clickhouse-server/config.xmlファイルはそのままにしておく/etc/clickhouse-server/users.xmlファイルはそのままにしておく
clickhouse-01の設定
clickhouse-01には5つの設定ファイルがあります。これらのファイルを1つのファイルにまとめることもできますが、ドキュメントの明確さのために別々に見るほうが簡単かもしれません。設定ファイルを読み進めると、ほとんどの設定がclickhouse-01とclickhouse-02で同じであることがわかり、違いは強調されています。
ネットワークとログの設定
これらの値はお好みに応じてカスタマイズできます。この例の設定では、以下を提供します:
- 1000Mのロールオーバーを3回行うデバッグログ
clickhouse-clientで接続したときに表示される名前はcluster_1S_2R node 1です- ClickHouseはポート8123と9000でIPV4ネットワークを介してリッスンします。
<clickhouse>
<logger>
<level>debug</level>
<log>/var/log/clickhouse-server/clickhouse-server.log</log>
<errorlog>/var/log/clickhouse-server/clickhouse-server.err.log</errorlog>
<size>1000M</size>
<count>3</count>
</logger>
<display_name>cluster_1S_2R node 1</display_name>
<listen_host>0.0.0.0</listen_host>
<http_port>8123</http_port>
<tcp_port>9000</tcp_port>
</clickhouse>
マクロの設定
マクロshardとreplicaは分散DDLの複雑さを軽減します。設定された値はDDLクエリで自動的に置き換えられ、DDLを簡単にします。この設定のマクロは、各ノードのシャード番号とレプリカ番号を指定します。
この1シャード2レプリカの例では、レプリカマクロはclickhouse-01でreplica_1、clickhouse-02でreplica_2です。シャードマクロは、1つのシャードしかないため、clickhouse-01とclickhouse-02の両方で1です。
<clickhouse>
<macros>
<shard>01</shard>
<replica>01</replica>
<cluster>cluster_1S_2R</cluster>
</macros>
</clickhouse>
レプリケーションとシャーディングの設定
上から始めて:
- XMLのremote_serversセクションは環境内の各クラスタを指定します。属性
replace=trueは、デフォルトのClickHouse設定内のサンプルremote_serversを、このファイル内で指定されたremote_server設定で置き換えます。この属性がない場合、このファイル内のリモートサーバーはデフォルトのサンプルリストに追加されます。 - この例では、
cluster_1S_2Rという名前のクラスタが1つあります。 cluster_1S_2Rという名前のクラスタには、値mysecretphraseのシークレットが作成されます。このシークレットは、環境内のすべてのリモートサーバー間で共有され、正しいサーバーが一緒に参加することを保証します。cluster_1S_2Rクラスタには1つのシャードと2つのレプリカがあります。このドキュメントの冒頭にあるアーキテクチャ図と、以下のXMLのシャード定義を比較してください。シャード定義には2つのレプリカが含まれています。各レプリカのホストとポートが指定されています。1つのレプリカはclickhouse-01に保存され、もう1つのレプリカはclickhouse-02に保存されます。- シャードの内部レプリケーションはtrueに設定されています。各シャードは、設定ファイルでinternal_replicationパラメータを定義できます。このパラメータがtrueに設定されている場合、書き込み操作は最初に健康なレプリカを選択してデータを書き込みます。
<clickhouse>
<remote_servers replace="true">
<cluster_1S_2R>
<secret>mysecretphrase</secret>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>clickhouse-01</host>
<port>9000</port>
</replica>
<replica>
<host>clickhouse-02</host>
<port>9000</port>
</replica>
</shard>
</cluster_1S_2R>
</remote_servers>
</clickhouse>
Keeperの使用を設定する
この設定ファイルuse-keeper.xmlは、ClickHouse Serverがレプリケーションと分散DDLの調整にClickHouse Keeperを使用するように設定しています。このファイルは、ClickHouse Serverがポート9181でノードclickhouse-keeper-01〜03上のKeeperを使用する必要があることを指定しており、clickhouse-01およびclickhouse-02で同じです。
<clickhouse>
<zookeeper>
<!-- where are the ZK nodes -->
<node>
<host>clickhouse-keeper-01</host>
<port>9181</port>
</node>
<node>
<host>clickhouse-keeper-02</host>
<port>9181</port>
</node>
<node>
<host>clickhouse-keeper-03</host>
<port>9181</port>
</node>
</zookeeper>
</clickhouse>
clickhouse-02の設定
設定は、clickhouse-01とclickhouse-02で非常に似ているため、ここでは違いのみを指摘します。
ネットワークとログの設定
このファイルは、display_nameを除き、clickhouse-01とclickhouse-02で同じです。
<clickhouse>
<logger>
<level>debug</level>
<log>/var/log/clickhouse-server/clickhouse-server.log</log>
<errorlog>/var/log/clickhouse-server/clickhouse-server.err.log</errorlog>
<size>1000M</size>
<count>3</count>
</logger>
<display_name>cluster_1S_2R node 2</display_name>
<listen_host>0.0.0.0</listen_host>
<http_port>8123</http_port>
<tcp_port>9000</tcp_port>
</clickhouse>
マクロの設定
マクロの設定はclickhouse-01とclickhouse-02で異なります。replicaはこのノードで02に設定されています。
<clickhouse>
<macros>
<shard>01</shard>
<replica>02</replica>
<cluster>cluster_1S_2R</cluster>
</macros>
</clickhouse>
レプリケーションとシャーディングの設定
このファイルは、clickhouse-01とclickhouse-02で同じです。
<clickhouse>
<remote_servers replace="true">
<cluster_1S_2R>
<secret>mysecretphrase</secret>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>clickhouse-01</host>
<port>9000</port>
</replica>
<replica>
<host>clickhouse-02</host>
<port>9000</port>
</replica>
</shard>
</cluster_1S_2R>
</remote_servers>
</clickhouse>
Keeperの使用を設定する
このファイルは、clickhouse-01とclickhouse-02で同じです。
<clickhouse>
<zookeeper>
<!-- where are the ZK nodes -->
<node>
<host>clickhouse-keeper-01</host>
<port>9181</port>
</node>
<node>
<host>clickhouse-keeper-02</host>
<port>9181</port>
</node>
<node>
<host>clickhouse-keeper-03</host>
<port>9181</port>
</node>
</zookeeper>
</clickhouse>
clickhouse-keeper-01の設定
ClickHouse Keeperを構成するために設定ファイルを編集する際には、以下を行うべきです:
/etc/clickhouse-keeper/keeper_config.xmlをバックアップする/etc/clickhouse-keeper/keeper_config.xmlファイルを編集する
ClickHouse Keeperは、データレプリケーションと分散DDLクエリの実行を調整するシステムを提供します。ClickHouse KeeperはApache ZooKeeperと互換性があります。この設定はポート9181でClickHouse Keeperを有効にします。強調されている行は、このKeeperのインスタンスがserver_id 1を持っていることを指定しています。これは、3つのサーバーすべてのenable-keeper.xmlファイルで唯一の違いです。clickhouse-keeper-02ではserver_idが2に設定され、clickhouse-keeper-03ではserver_idが3に設定されます。raft設定セクションは3台のサーバーすべてで同じであり、server_idとraft設定内のserverインスタンスの関係を示すために以下で強調されています。
なんらかの理由でKeeperノードが置き換えられたり再構築されたりした場合、既存のserver_idを再利用しないでください。例えば、server_idが2のKeeperノードが再構築された場合、server_idを4以上に設定してください。
<clickhouse>
<logger>
<level>trace</level>
<log>/var/log/clickhouse-keeper/clickhouse-keeper.log</log>
<errorlog>/var/log/clickhouse-keeper/clickhouse-keeper.err.log</errorlog>
<size>1000M</size>
<count>3</count>
</logger>
<listen_host>0.0.0.0</listen_host>
<keeper_server>
<tcp_port>9181</tcp_port>
<server_id>1</server_id>
<log_storage_path>/var/lib/clickhouse/coordination/log</log_storage_path>
<snapshot_storage_path>/var/lib/clickhouse/coordination/snapshots</snapshot_storage_path>
<coordination_settings>
<operation_timeout_ms>10000</operation_timeout_ms>
<session_timeout_ms>30000</session_timeout_ms>
<raft_logs_level>trace</raft_logs_level>
</coordination_settings>
<raft_configuration>
<server>
<id>1</id>
<hostname>clickhouse-keeper-01</hostname>
<port>9234</port>
</server>
<server>
<id>2</id>
<hostname>clickhouse-keeper-02</hostname>
<port>9234</port>
</server>
<server>
<id>3</id>
<hostname>clickhouse-keeper-03</hostname>
<port>9234</port>
</server>
</raft_configuration>
</keeper_server>
</clickhouse>
clickhouse-keeper-02の設定
clickhouse-keeper-01とclickhouse-keeper-02間には1行の違いしかありません。このノードではserver_idが2に設定されています。
<clickhouse>
<logger>
<level>trace</level>
<log>/var/log/clickhouse-keeper/clickhouse-keeper.log</log>
<errorlog>/var/log/clickhouse-keeper/clickhouse-keeper.err.log</errorlog>
<size>1000M</size>
<count>3</count>
</logger>
<listen_host>0.0.0.0</listen_host>
<keeper_server>
<tcp_port>9181</tcp_port>
<server_id>2</server_id>
<log_storage_path>/var/lib/clickhouse/coordination/log</log_storage_path>
<snapshot_storage_path>/var/lib/clickhouse/coordination/snapshots</snapshot_storage_path>
<coordination_settings>
<operation_timeout_ms>10000</operation_timeout_ms>
<session_timeout_ms>30000</session_timeout_ms>
<raft_logs_level>trace</raft_logs_level>
</coordination_settings>
<raft_configuration>
<server>
<id>1</id>
<hostname>clickhouse-keeper-01</hostname>
<port>9234</port>
</server>
<server>
<id>2</id>
<hostname>clickhouse-keeper-02</hostname>
<port>9234</port>
</server>
<server>
<id>3</id>
<hostname>clickhouse-keeper-03</hostname>
<port>9234</port>
</server>
</raft_configuration>
</keeper_server>
</clickhouse>
clickhouse-keeper-03の設定
clickhouse-keeper-01とclickhouse-keeper-03間には1行の違いしかありません。このノードではserver_idが3に設定されています。
<clickhouse>
<logger>
<level>trace</level>
<log>/var/log/clickhouse-keeper/clickhouse-keeper.log</log>
<errorlog>/var/log/clickhouse-keeper/clickhouse-keeper.err.log</errorlog>
<size>1000M</size>
<count>3</count>
</logger>
<listen_host>0.0.0.0</listen_host>
<keeper_server>
<tcp_port>9181</tcp_port>
<server_id>3</server_id>
<log_storage_path>/var/lib/clickhouse/coordination/log</log_storage_path>
<snapshot_storage_path>/var/lib/clickhouse/coordination/snapshots</snapshot_storage_path>
<coordination_settings>
<operation_timeout_ms>10000</operation_timeout_ms>
<session_timeout_ms>30000</session_timeout_ms>
<raft_logs_level>trace</raft_logs_level>
</coordination_settings>
<raft_configuration>
<server>
<id>1</id>
<hostname>clickhouse-keeper-01</hostname>
<port>9234</port>
</server>
<server>
<id>2</id>
<hostname>clickhouse-keeper-02</hostname>
<port>9234</port>
</server>
<server>
<id>3</id>
<hostname>clickhouse-keeper-03</hostname>
<port>9234</port>
</server>
</raft_configuration>
</keeper_server>
</clickhouse>
テスト
ReplicatedMergeTreeとClickHouse Keeperの経験を得るために、以下のコマンドを実行してみてください。これにより、以下の操作が行えます:
- 上記で設定されたクラスタにデータベースを作成する
- ReplicatedMergeTreeテーブルエンジンを使用してデータベースにテーブルを作成する
- 1つのノードにデータを挿入し、別のノードでクエリを実行する
- 1つのClickHouseサーバーノードを停止する
- 動作中のノードにさらにデータを挿入する
- 停止したノードを再起動する
- 再起動したノードでクエリを実行して、データが利用可能であることを確認する
ClickHouse Keeperが動作していることを確認する
mntrコマンドは、ClickHouse Keeperが動作していることを確認し、3つのKeeperノードの関係に関する状態情報を得るために使用されます。この例で使用されている設定では、3つのノードが一緒に動作します。ノードはリーダーを選出し、残りのノードはフォロワーになります。mntrコマンドは、パフォーマンスに関連する情報や、特定のノードがフォロワーかリーダーであるかを示します。
Keeperにmntrコマンドを送信するためにnetcatをインストールする必要があるかもしれません。ダウンロード情報についてはnmap.orgページをご覧ください。
echo mntr | nc localhost 9181
zk_version v23.3.1.2823-testing-46e85357ce2da2a99f56ee83a079e892d7ec3726
zk_avg_latency 0
zk_max_latency 0
zk_min_latency 0
zk_packets_received 0
zk_packets_sent 0
zk_num_alive_connections 0
zk_outstanding_requests 0
zk_server_state follower
zk_znode_count 6
zk_watch_count 0
zk_ephemerals_count 0
zk_approximate_data_size 1271
zk_key_arena_size 4096
zk_latest_snapshot_size 0
zk_open_file_descriptor_count 46
zk_max_file_descriptor_count 18446744073709551615
zk_version v23.3.1.2823-testing-46e85357ce2da2a99f56ee83a079e892d7ec3726
zk_avg_latency 0
zk_max_latency 0
zk_min_latency 0
zk_packets_received 0
zk_packets_sent 0
zk_num_alive_connections 0
zk_outstanding_requests 0
zk_server_state leader
zk_znode_count 6
zk_watch_count 0
zk_ephemerals_count 0
zk_approximate_data_size 1271
zk_key_arena_size 4096
zk_latest_snapshot_size 0
zk_open_file_descriptor_count 48
zk_max_file_descriptor_count 18446744073709551615
zk_followers 2
zk_synced_followers 2
ClickHouseクラスタの機能を確認する
1つのシェルでclickhouse-01にclickhouse clientで接続し、もう1つのシェルでclickhouse-02にclickhouse clientで接続します。
- 上記で設定されたクラスタにデータベースを作成する
CREATE DATABASE db1 ON CLUSTER cluster_1S_2R
┌─host──────────┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ clickhouse-02 │ 9000 │ 0 │ │ 1 │ 0 │
│ clickhouse-01 │ 9000 │ 0 │ │ 0 │ 0 │
└───────────────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
- ReplicatedMergeTreeテーブルエンジンを使用してデータベースにテーブルを作成する
CREATE TABLE db1.table1 ON CLUSTER cluster_1S_2R
(
`id` UInt64,
`column1` String
)
ENGINE = ReplicatedMergeTree
ORDER BY id
┌─host──────────┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ clickhouse-02 │ 9000 │ 0 │ │ 1 │ 0 │
│ clickhouse-01 │ 9000 │ 0 │ │ 0 │ 0 │
└───────────────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
- 1つのノードでデータを挿入し、別のノードでクエリを実行する
INSERT INTO db1.table1 (id, column1) VALUES (1, 'abc');
- ノード
clickhouse-02でテーブルをクエリする
SELECT *
FROM db1.table1
┌─id─┬─column1─┐
│ 1 │ abc │
└────┴─────────┘
- 他のノードでデータを挿入し、ノード
clickhouse-01でクエリを実行する
INSERT INTO db1.table1 (id, column1) VALUES (2, 'def');
SELECT *
FROM db1.table1
┌─id─┬─column1─┐
│ 1 │ abc │
└────┴─────────┘
┌─id─┬─column1─┐
│ 2 │ def │
└────┴─────────┘
1台のClickHouseサーバーノードを停止する 1台のClickHouseサーバーノードを停止するには、ノードの起動に使用したものと似たオペレーティングシステムコマンドを実行します。
systemctl startでノードを起動した場合、systemctl stopを使用して停止します。動作中のノードにさらにデータを挿入する
INSERT INTO db1.table1 (id, column1) VALUES (3, 'ghi');
データを選択します:
SELECT *
FROM db1.table1
┌─id─┬─column1─┐
│ 1 │ abc │
└────┴─────────┘
┌─id─┬─column1─┐
│ 2 │ def │
└────┴─────────┘
┌─id─┬─column1─┐
│ 3 │ ghi │
└────┴─────────┘
- 停止したノードを再起動し、そこでも選択する
SELECT *
FROM db1.table1
┌─id─┬─column1─┐
│ 1 │ abc │
└────┴─────────┘
┌─id─┬─column1─┐
│ 2 │ def │
└────┴─────────┘
┌─id─┬─column1─┐
│ 3 │ ghi │
└────┴─────────┘