Apache NiFiをClickHouseに接続
Apache NiFiは、オープンソースのワークフロー管理ソフトウェアで、ソフトウェアシステム間のデータフローを自動化するために設計されています。ETLデータパイプラインを作成することができ、300以上のデータプロセッサが用意されています。このステップバイステップのチュートリアルでは、Apache NiFiをClickHouseにソースおよびデスティネーションとして接続し、サンプルデータセットをロードする方法を示します。1. 接続情報を集める
HTTP(S) を使用して ClickHouse に接続するには、以下の情報が必要です:
HOST と PORT: 通常、TLS を使用する場合のポートは 8443、TLS を使用しない場合は 8123 です。
データベース名: デフォルトで
defaultという名前のデータベースがありますが、接続したいデータベースの名前を使用してください。ユーザー名とパスワード: デフォルトでユーザー名は
defaultです。使用ケースに適したユーザー名を使用してください。
ClickHouse Cloud サービスの詳細は、ClickHouse Cloud コンソールで確認できます。 接続するサービスを選択し、接続 をクリックします:
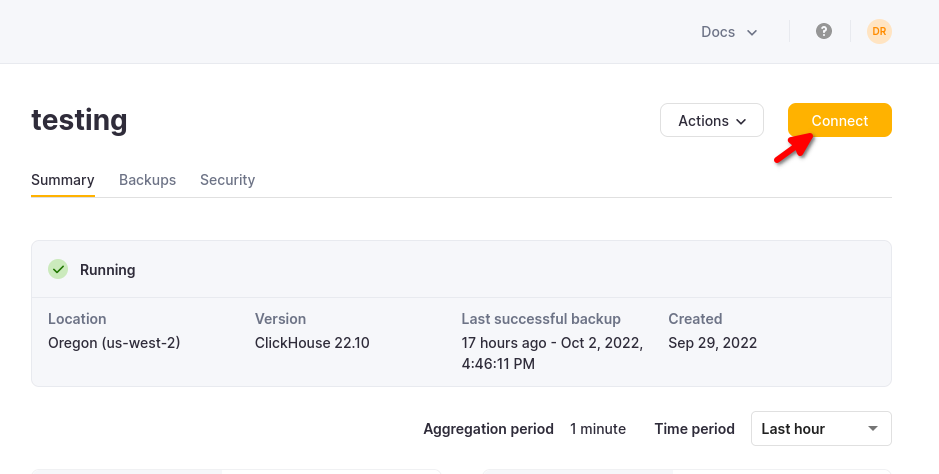
HTTPS を選択すると、サンプルの curl コマンドで詳細が確認できます。
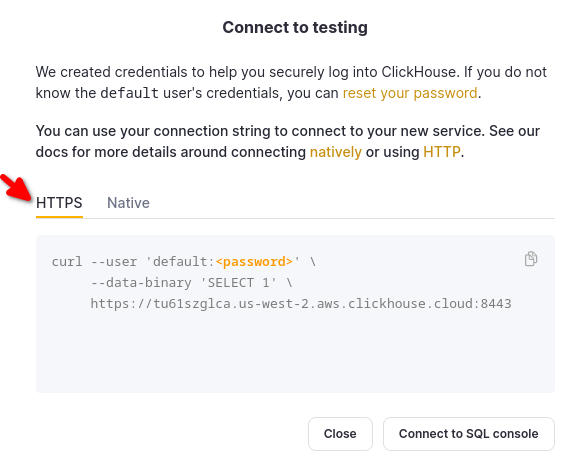
セルフマネージドの ClickHouse を使用している場合、接続の詳細は ClickHouse 管理者によって設定されます。
2. Apache NiFiをダウンロードして実行
- 新しいセットアップのために、https://nifi.apache.org/download.html からバイナリをダウンロードし、
./bin/nifi.sh startを実行して開始します。
3. ClickHouse JDBCドライバーをダウンロード
- GitHubのClickHouse JDBCドライバーリリースページを訪問し、最新のJDBCリリース版を探します。
- リリースバージョンで「Show all xx assets」をクリックし、「shaded」または「all」のキーワードを含むJARファイル、例えば
clickhouse-jdbc-0.5.0-all.jarを探します。 - JARファイルをApache NiFiがアクセスできるフォルダーに配置し、絶対パスをメモしておきます。
4. DBCPConnectionPoolコントローラーサービスを追加してプロパティを設定
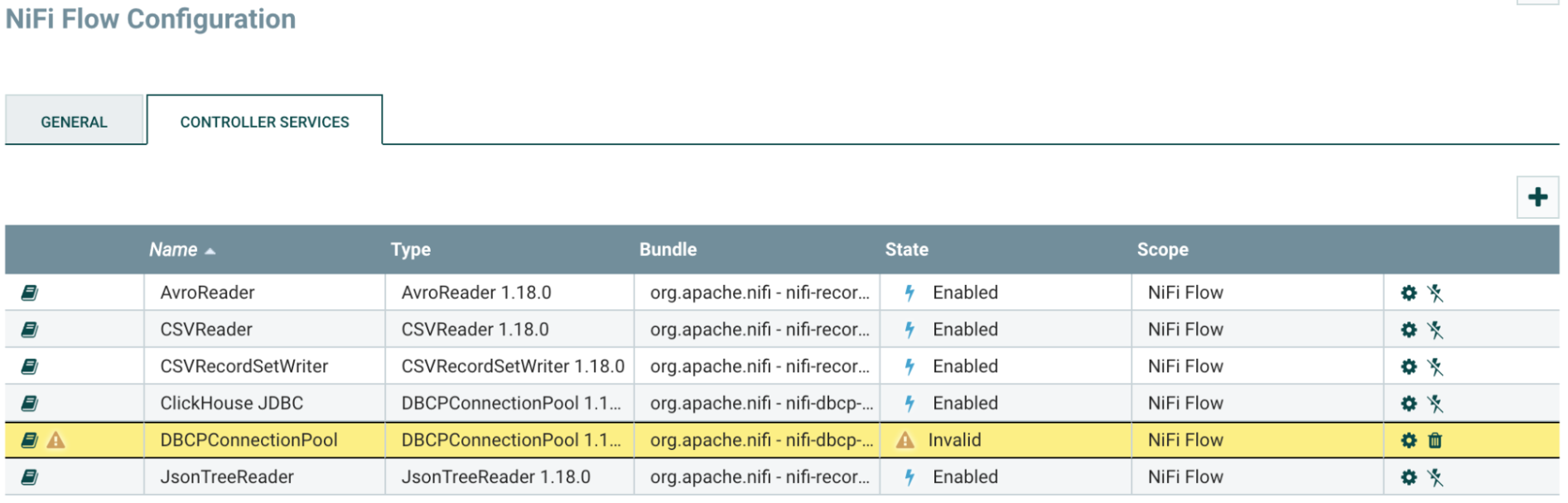
Apache NiFiでコントローラーサービスを設定するために、「歯車」ボタンをクリックしてNiFiフロー構成ページにアクセスします。
コントローラーサービスタブを選択し、右上の
+ボタンをクリックして新しいコントローラーサービスを追加します。
DBCPConnectionPoolを検索して「Add」ボタンをクリックします。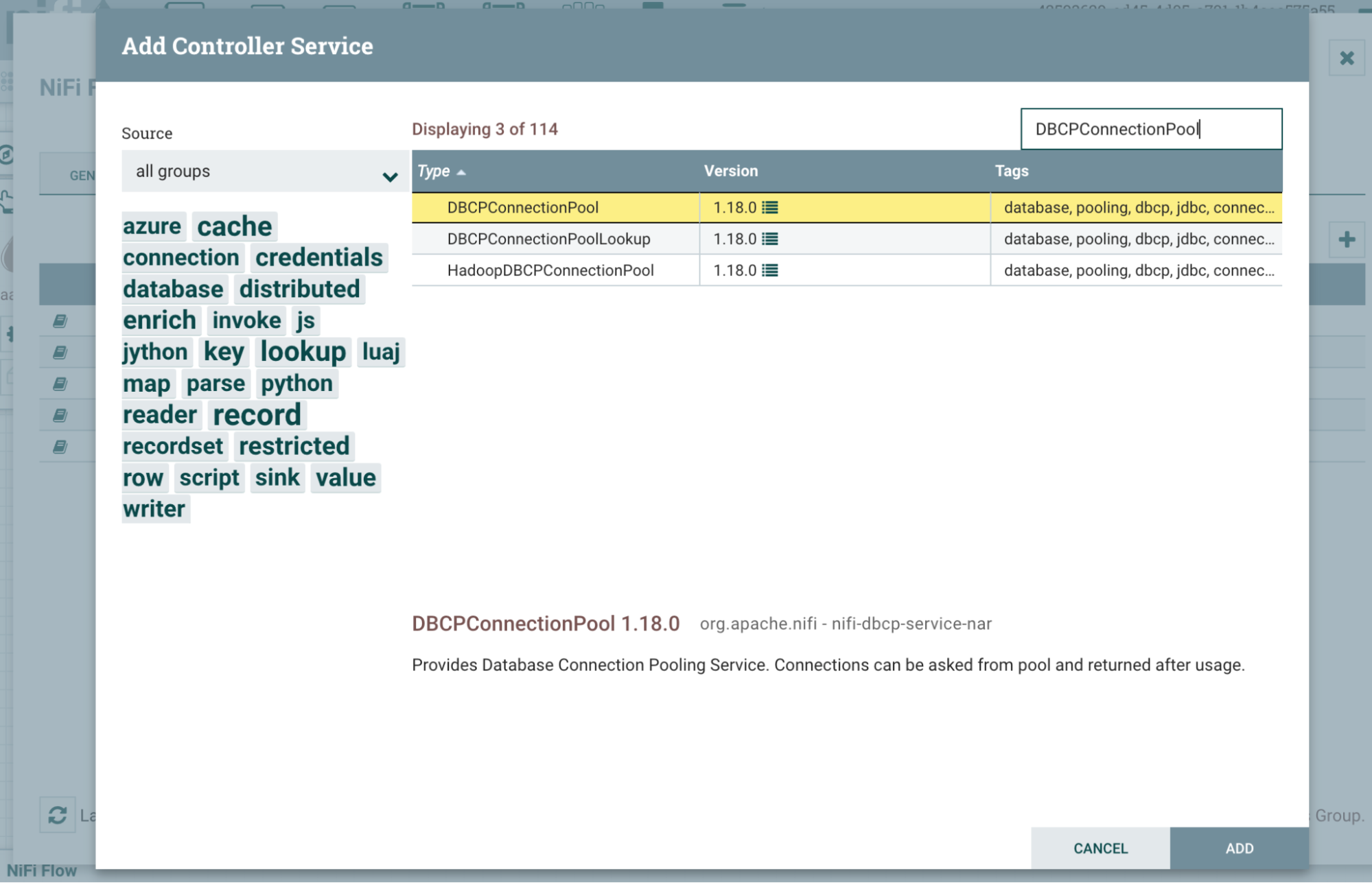
新しく追加されたDBCPConnectionPoolはデフォルトで無効な状態になります。「歯車」ボタンをクリックして設定を開始します。
「プロパティ」セクションの下に以下の値を入力します。
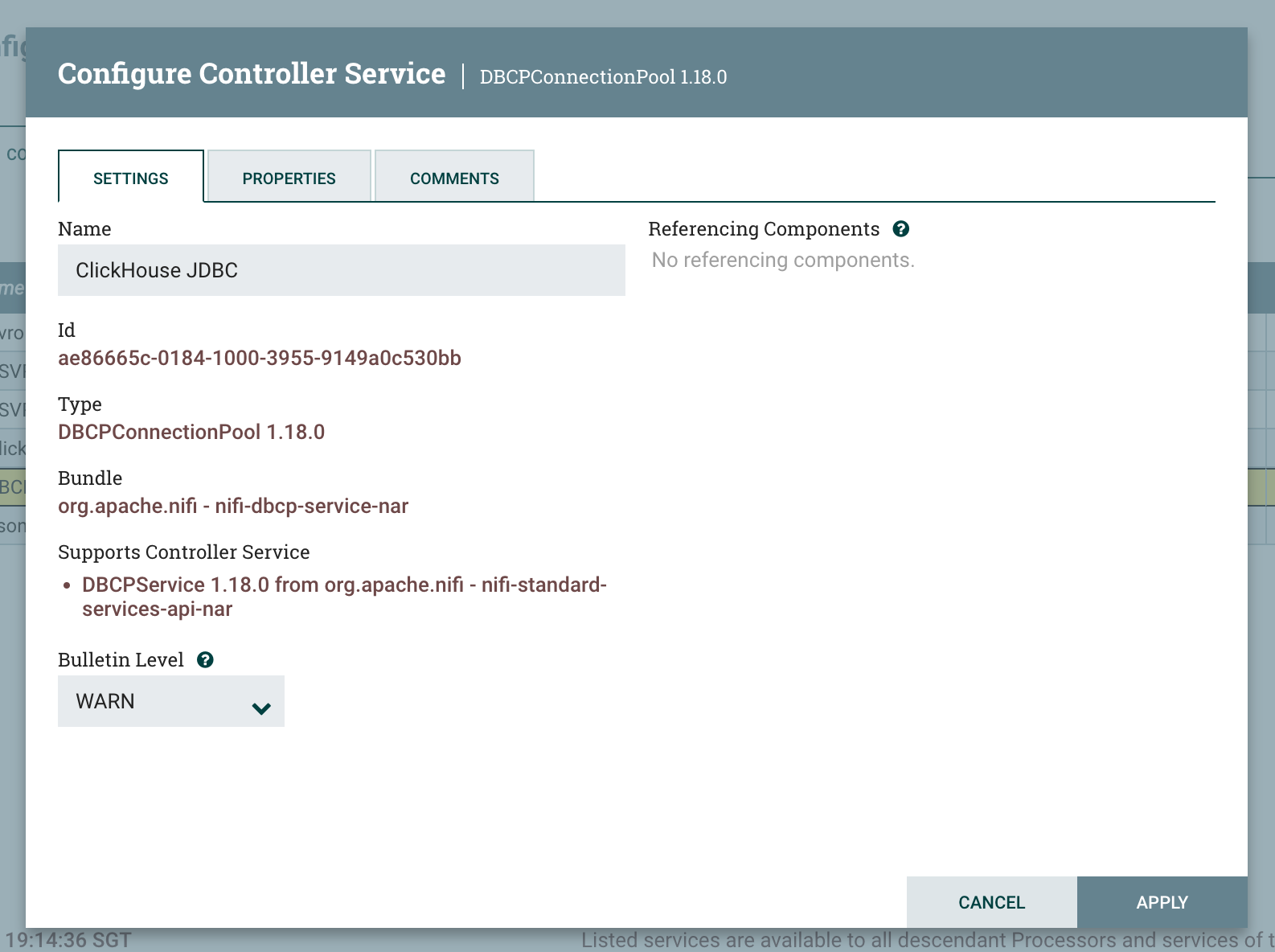
プロパティ 値 備考 Database Connection URL jdbc:ch:https://HOSTNAME:8443/default?ssl=true 接続URLに応じてHOSTNAMEを置き換える Database Driver Class Name com.clickhouse.jdbc.ClickHouseDriver Database Driver Location(s) /etc/nifi/nifi-X.XX.X/lib/clickhouse-jdbc-0.X.X-patchXX-shaded.jar ClickHouse JDBCドライバJARファイルへの絶対パス Database User default ClickHouseのユーザー名 Password password ClickHouseのパスワード 設定セクションで、コントローラーサービスの名前を「ClickHouse JDBC」に変更し、参照しやすいようにします。
DBCPConnectionPoolコントローラーサービスを有効化するために「稲妻」ボタンをクリックし、「Enable」ボタンを押します。
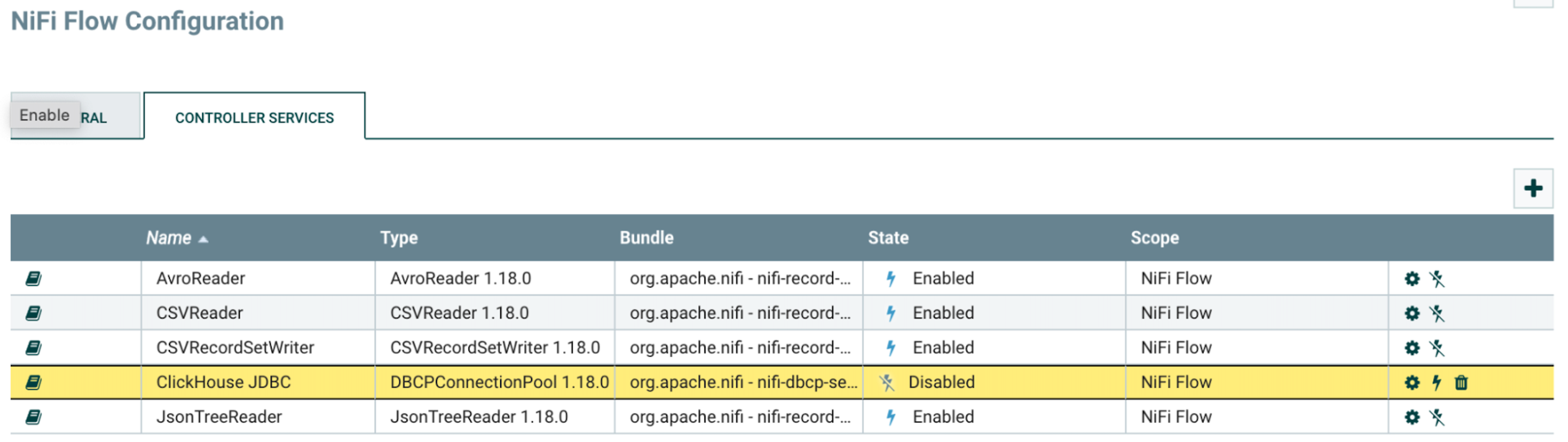
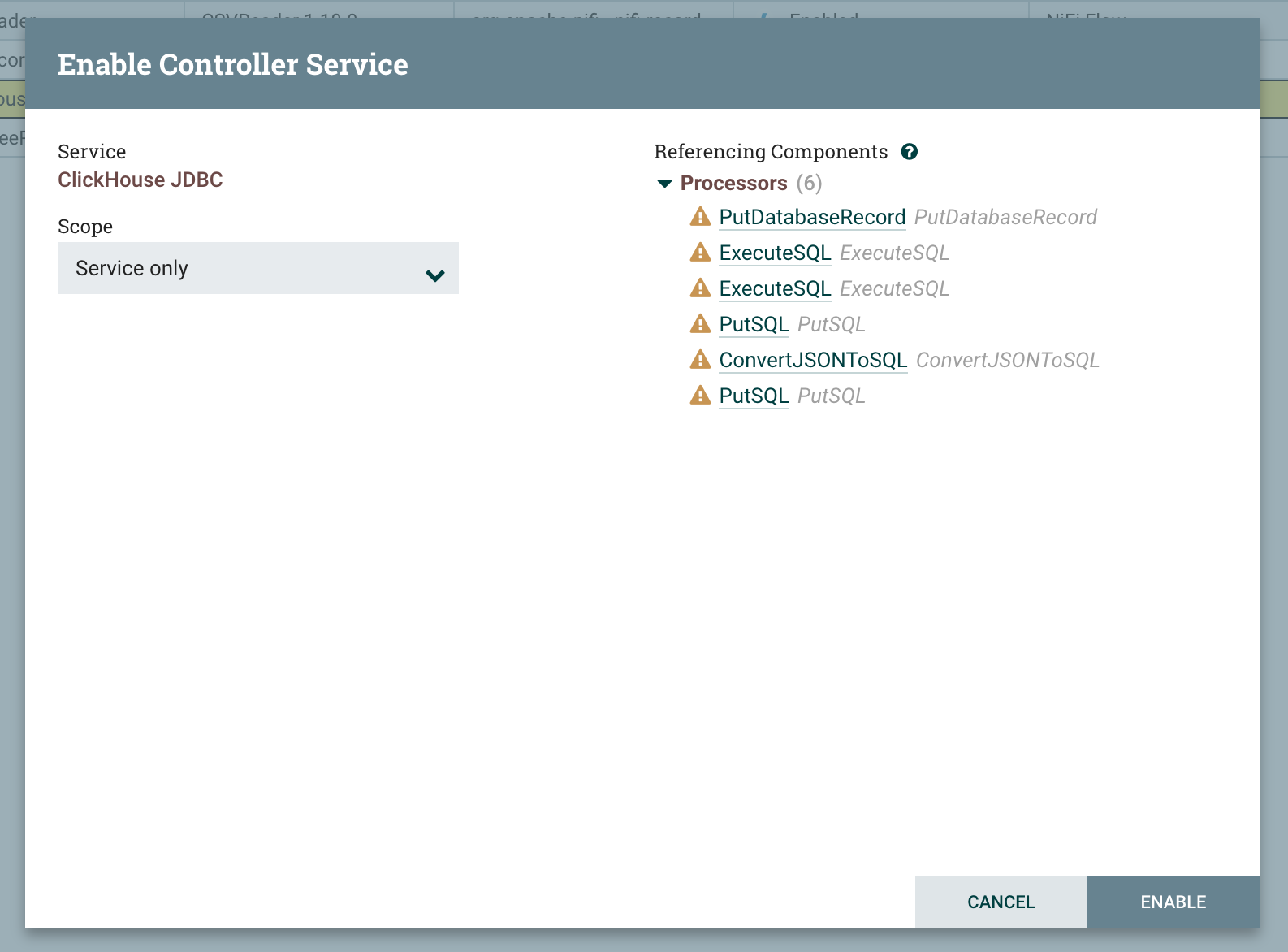
コントローラーサービスタブを確認し、コントローラーサービスが有効になっていることを確かめます。

5. ExecuteSQLプロセッサを使用してテーブルから読み込み
ExecuteSQLプロセッサを追加し、適切な上流および下流のプロセッサを設定します。
ExecuteSQLプロセッサの「プロパティ」セクションの下に以下の値を入力します。
プロパティ 値 備考 Database Connection Pooling Service ClickHouse JDBC ClickHouse用に設定されたコントローラーサービスを選択 SQL select query SELECT * FROM system.metrics ここにクエリを入力 ExecuteSQLプロセッサを開始します。
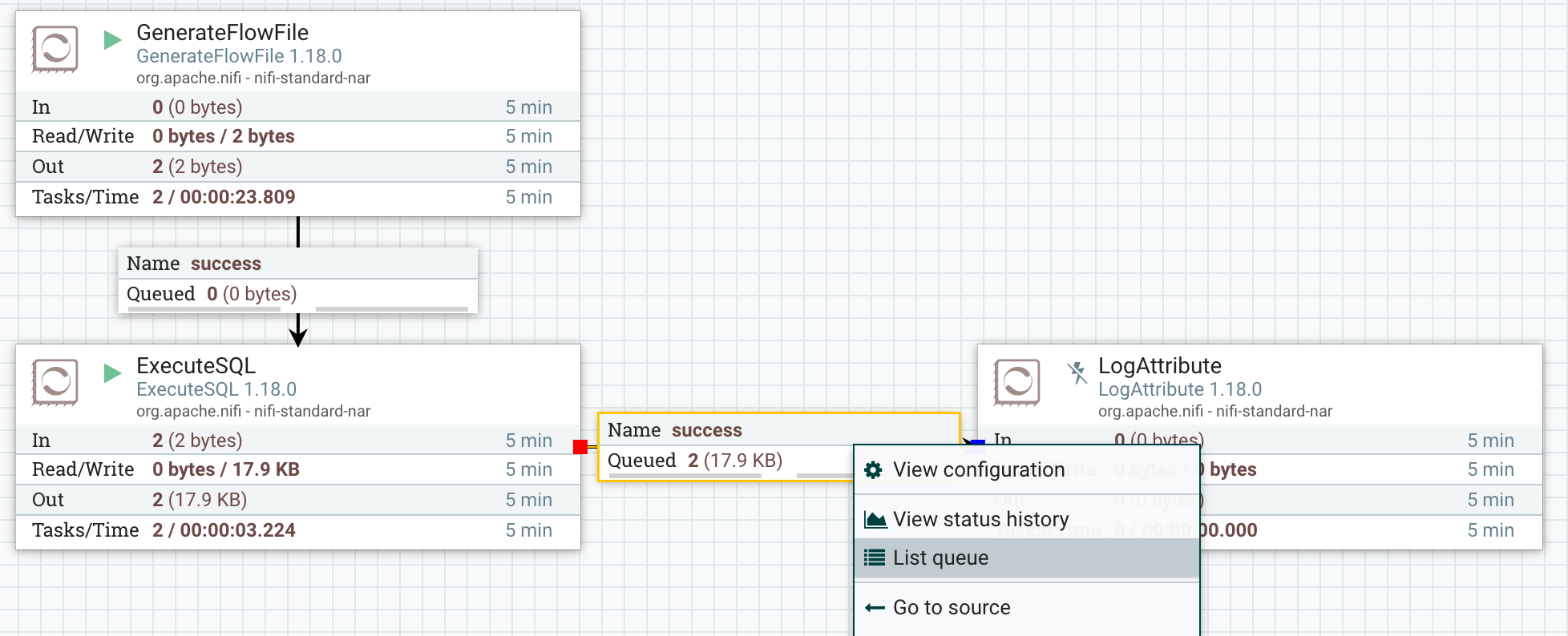
クエリが正常に処理されたことを確認するために、出力キューのFlowFileを確認します。
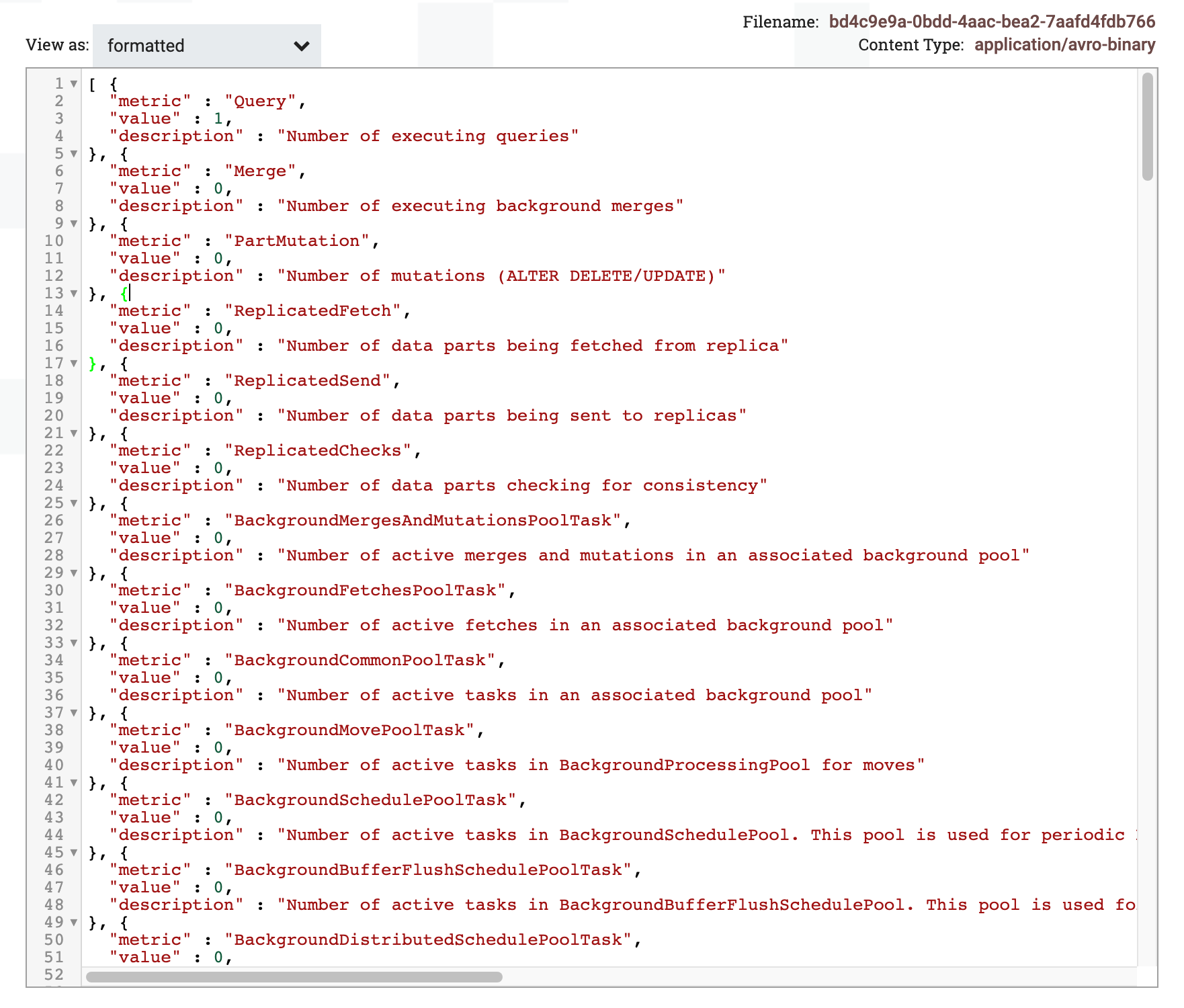
出力FlowFileの結果をフォーマット表示で確認します。
6. MergeRecordとPutDatabaseRecordプロセッサを使用してテーブルに書き込み
複数の行を一度に挿入するには、まず複数のレコードを単一のレコードにマージする必要があります。これにはMergeRecordプロセッサを使用します。
MergeRecordプロセッサの「プロパティ」セクションの下に以下の値を入力します。
プロパティ 値 備考 Record Reader JSONTreeReader 適切なレコードリーダーを選択 Record Writer JSONReadSetWriter 適切なレコードライターを選択 Minimum Number of Records 1000 最低限マージされる必要がある行数を増やします。デフォルトは1行 Maximum Number of Records 10000 「Minimum Number of Records」より大きい値にします。デフォルトは1,000行 複数のレコードが1つにマージされていることを確認するために、MergeRecordプロセッサの入力と出力を確認します。出力は複数の入力レコードの配列です。
入力
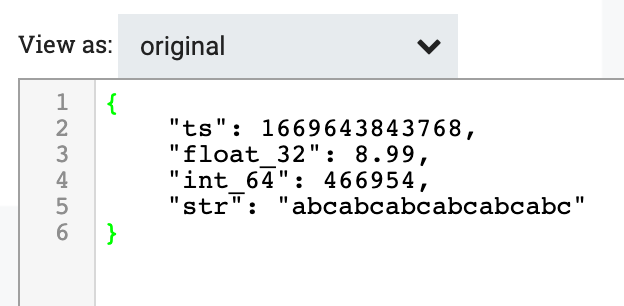
出力
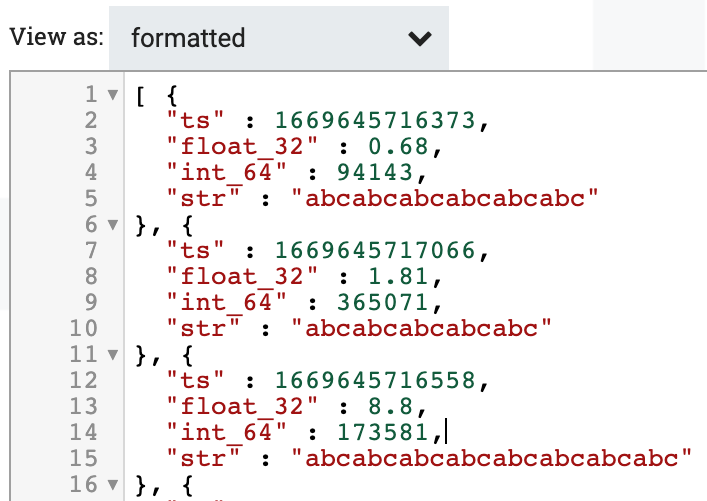
PutDatabaseRecordプロセッサの「プロパティ」セクションの下に以下の値を入力します。
プロパティ 値 備考 Record Reader JSONTreeReader 適切なレコードリーダーを選択 Database Type Generic デフォルトのままにします Statement Type INSERT Database Connection Pooling Service ClickHouse JDBC ClickHouseコントローラーサービスを選択 Table Name tbl テーブル名をここに入力 Translate Field Names false 挿入されるフィールド名がカラム名と一致する必要がある場合は「false」に設定 Maximum Batch Size 1000 挿入ごとの最大行数。この値はMergeRecordプロセッサの「Minimum Number of Records」の値より小さくしてはいけません。 各挿入に複数の行が含まれていることを確認するために、MergeRecordで定義された「Minimum Number of Records」の値以上にテーブルの行数が増加しているか確認します。
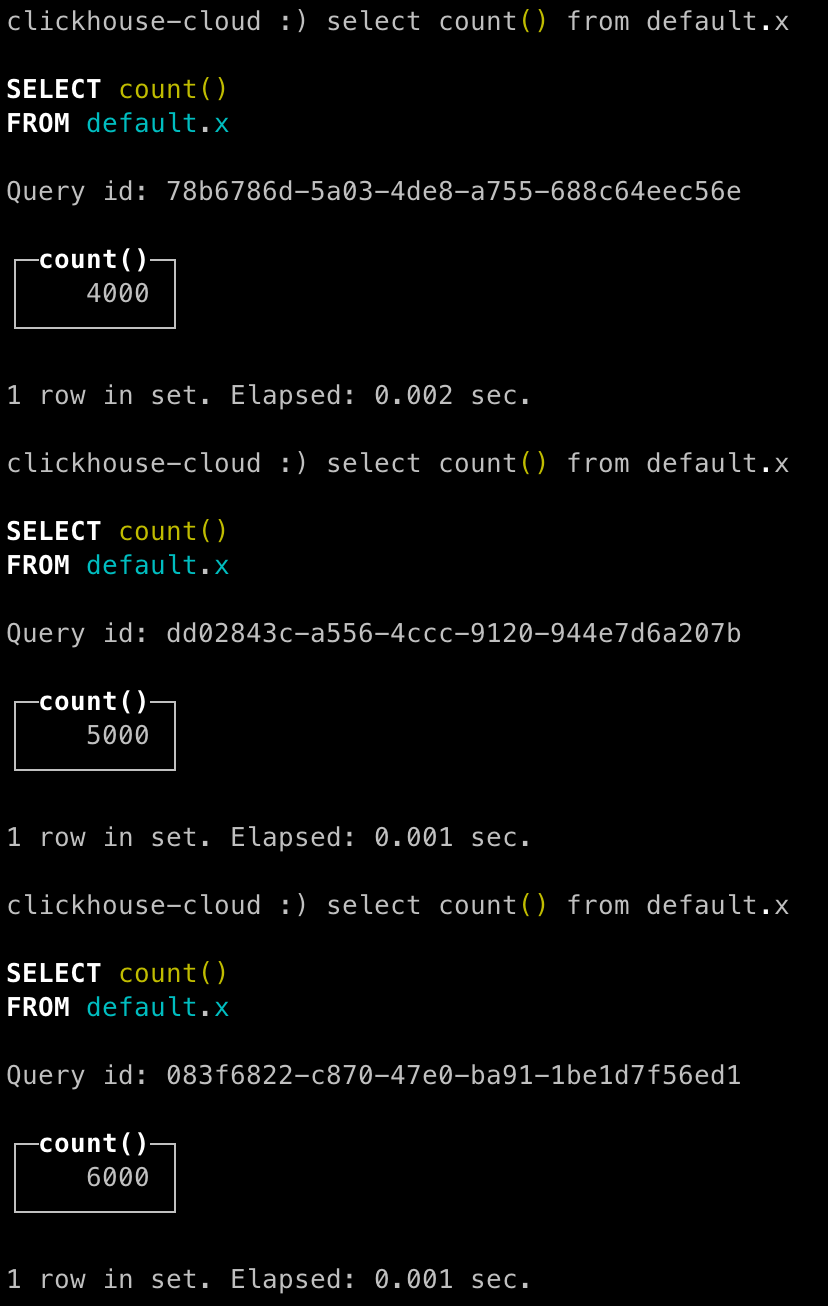
おめでとうございます - Apache NiFiを使用してClickHouseにデータを正常にロードしました!