ClickHouse Kafka Connect Sink
サポートが必要な場合は、このリポジトリで問題を報告するか、ClickHouseの公的Slackで質問してください。
ClickHouse Kafka Connect Sink は、KafkaトピックからClickHouseテーブルにデータを転送するKafkaコネクタです。
ライセンス
Kafka Connector Sink は Apache 2.0 License の下で配布されています。
環境要件
環境に Kafka Connect フレームワークv2.7以上をインストールする必要があります。
バージョン互換性マトリックス
| ClickHouse Kafka Connect バージョン | ClickHouse バージョン | Kafka Connect | Confluent プラットフォーム |
|---|---|---|---|
| 1.0.0 | > 23.3 | > 2.7 | > 6.1 |
主な特徴
- 標準でExactly-onceセマンティクスを提供。新しいClickHouseのコア機能KeepeMapにより実現され、最小限のアーキテクチャが可能です。
- サードパーティのステートストアのサポート:現在はIn-memoryがデフォルトですが、KeeperMapを使用できます(Redisは近日追加予定)。
- コア統合:ClickHouseによって構築、保守、およびサポートされています。
- ClickHouse Cloudに対して継続的にテストされています。
- 宣言されたスキーマとスキーマレスでのデータ挿入。
- 全てのClickHouseデータタイプに対応。
インストール手順
接続情報を収集する
HTTP(S) を使用して ClickHouse に接続するには、以下の情報が必要です:
HOST と PORT: 通常、TLS を使用する場合のポートは 8443、TLS を使用しない場合は 8123 です。
データベース名: デフォルトで
defaultという名前のデータベースがありますが、接続したいデータベースの名前を使用してください。ユーザー名とパスワード: デフォルトでユーザー名は
defaultです。使用ケースに適したユーザー名を使用してください。
ClickHouse Cloud サービスの詳細は、ClickHouse Cloud コンソールで確認できます。 接続するサービスを選択し、接続 をクリックします:
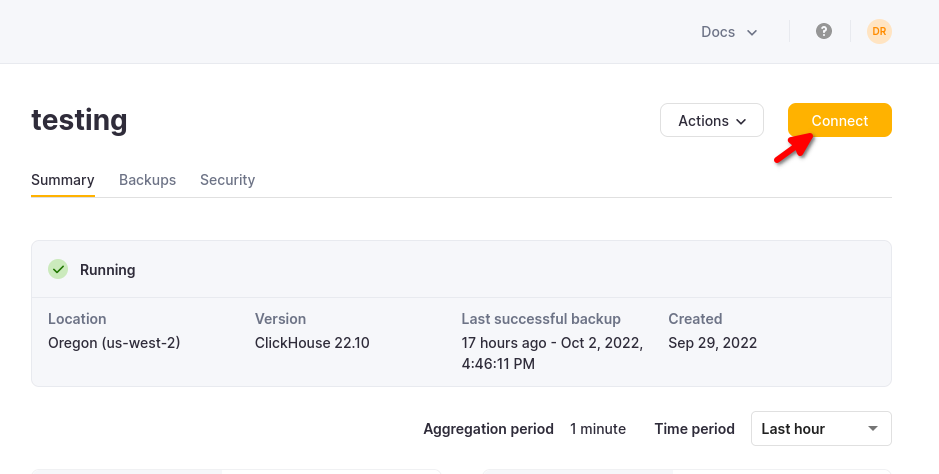
HTTPS を選択すると、サンプルの curl コマンドで詳細が確認できます。
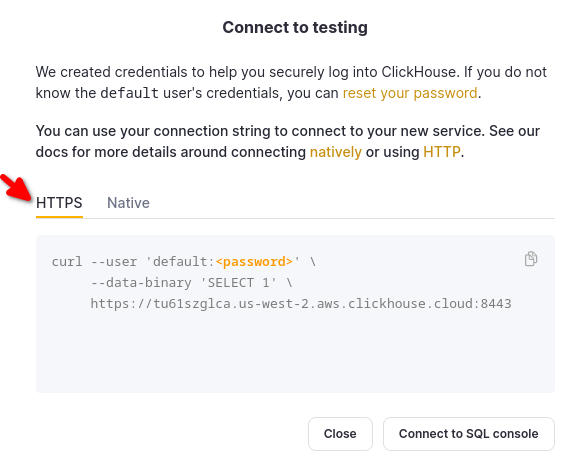
セルフマネージドの ClickHouse を使用している場合、接続の詳細は ClickHouse 管理者によって設定されます。
一般的なインストール手順
コネクタは、プラグインを実行するために必要なすべてのクラスファイルを含む単一のUber JARファイルとして配布されます。
プラグインをインストールするには、以下の手順を実行してください:
- ClickHouse Kafka Connect Sink リポジトリの リリース ページからコネクタ JAR ファイルを含む ZIP アーカイブをダウンロードします。
- ZIP ファイルの内容を展開し、目的の場所にコピーします。
- プラグインを Confluent Platform が見つけることができるように、Connect プロパティファイルの plugin.path 設定にプラグインディレクトリを追加します。
- トピック名、ClickHouseインスタンスのホスト名、およびパスワードを設定します。
connector.class=com.clickhouse.kafka.connect.ClickHouseSinkConnector
tasks.max=1
topics=<topic_name>
ssl=true
jdbcConnectionProperties=?sslmode=STRICT
security.protocol=SSL
hostname=<hostname>
database=<database_name>
password=<password>
ssl.truststore.location=/tmp/kafka.client.truststore.jks
port=8443
value.converter.schemas.enable=false
value.converter=org.apache.kafka.connect.json.JsonConverter
exactlyOnce=true
username=default
schemas.enable=false
- Confluent Platformを再起動します。
- Confluent Platformを使用している場合、Confluent Control Center UI にログインして、ClickHouse Sink が利用可能なコネクタのリストに表示されているか確認します。
設定オプション
ClickHouse Sink を ClickHouseサーバーに接続するには、以下の情報を提供する必要があります:
- 接続詳細:ホスト名(必須)とポート(オプション)
- ユーザー資格情報:パスワード(必須)とユーザー名(オプション)
- コネクタクラス:
com.clickhouse.kafka.connect.ClickHouseSinkConnector(必須) - トピックまたは topics.regex: ポーリングするKafka トピック - トピック名はテーブル名と一致している必要があります(必須)
- キーと値のコンバーター:トピック内のデータのタイプに基づいて設定します。ワーカ設定で定義されていない場合に必要です。
設定オプションの全表:
| プロパティ名 | 説明 | デフォルト値 |
|---|---|---|
hostname (必須) | サーバーのホスト名またはIPアドレス | N/A |
port | ClickHouseのポート - デフォルトは8443(クラウドではHTTPS用)ですが、HTTP(自ホストデフォルトの場合)を使用する場合は8123にする必要があります | 8443 |
ssl | ClickHouseへのSSL接続を有効にする | true |
jdbcConnectionProperties | ClickHouseへの接続時のプロパティ。?で始まり、param=value間は&で結合される必要があります | "" |
username | ClickHouseのデータベースユーザー名 | default |
password (必須) | ClickHouseのデータベースパスワード | N/A |
database | ClickHouseのデータベース名 | default |
connector.class (必須) | コネクタクラス(デフォルト値として明示的に設定してください) | "com.clickhouse.kafka.connect.ClickHouseSinkConnector" |
tasks.max | コネクタタスクの数 | "1" |
errors.retry.timeout | ClickHouse JDBC リトライタイムアウト | "60" |
exactlyOnce | Exactly Once 有効 | "false" |
topics (必須) | ポーリングするKafkaトピック - トピック名はテーブル名と一致する必要があります | "" |
key.converter (必須 - 説明参照) | キーのタイプに応じて設定します。キーを渡している場合(ワーカ設定で定義されていない場合)はここで必要です。 | "org.apache.kafka.connect.storage.StringConverter" |
value.converter (必須 - 説明参照) | トピック内のデータのタイプに基づいて設定します。サポートされる形式:- JSON、String、AvroまたはProtobuf フォーマット。ワーカ設定で定義されていない場合にここで必要です。 | "org.apache.kafka.connect.json.JsonConverter" |
value.converter.schemas.enable | コネクタ値コンバータスキーマサポート | "false" |
errors.tolerance | コネクタエラートレランス。サポートされる値:none、all | "none" |
errors.deadletterqueue.topic.name | セットされている場合(errors.tolerance=allの場合)、失敗したバッチに対してDLQが使用されます(トラブルシューティングを参照) | "" |
errors.deadletterqueue.context.headers.enable | DLQに追加のヘッダーを追加します | "" |
clickhouseSettings | ClickHouse設定のコンマ区切りリスト(例: "insert_quorum=2, など...") | "" |
topic2TableMap | トピック名をテーブル名にマッピングするカンマ区切りリスト(例: "topic1=table1, topic2=table2, など...") | "" |
tableRefreshInterval | テーブル定義キャッシュの更新間隔(秒単位) | 0 |
keeperOnCluster | 自ホストインスタンスのために ON CLUSTER パラメータを設定可能にします(例: " ON CLUSTER clusterNameInConfigFileDefinition ")exactly-once connect_state テーブル用(分散DDLクエリ参照) | "" |
bypassRowBinary | スキーマベースのデータ(Avro、Protobufなど)に対するRowBinaryおよびRowBinaryWithDefaultsの使用を無効にすることができます - 欠損カラムがある場合や、Nullable/Defaultが許容できない場合にのみ使用してください | "false" |
dateTimeFormats | DateTime64スキーマフィールドを解析するための日付時間形式、-で区切ります(例: 'someDateField=yyyy-MM-dd HH:mm:ss.SSSSSSSSS;someOtherDateField=yyyy-MM-dd HH:mm:ss')。 | "" |
tolerateStateMismatch | 現在のオフセットよりも"早い"レコードを削除できるようにコネクタを設定します(例: オフセット5が送信され、最後に記録されたオフセットが250の場合) | "false" |
ターゲットテーブル
ClickHouse Connect SinkはKafkaトピックからメッセージを読み取り、適切なテーブルに書き込みます。ClickHouse Connect Sinkは既存のテーブルにデータを書き込みます。データを挿入する前に、ClickHouseに適切なスキーマを持つターゲットテーブルが作成されていることを確認してください。
各トピックにはClickHouse内で専用のターゲットテーブルが必要です。ターゲットテーブル名はソーストピック名と一致している必要があります。
前処理
ClickHouse Kafka Connect Sinkに送信される前にアウトバウンドメッセージを変換する必要がある場合は、Kafka Connect Transformations を使用してください。
サポートされているデータ型
スキーマ宣言あり:
| Kafka Connect タイプ | ClickHouse タイプ | サポート | プリミティブ |
|---|---|---|---|
| STRING | String | ✅ | Yes |
| INT8 | Int8 | ✅ | Yes |
| INT16 | Int16 | ✅ | Yes |
| INT32 | Int32 | ✅ | Yes |
| INT64 | Int64 | ✅ | Yes |
| FLOAT32 | Float32 | ✅ | Yes |
| FLOAT64 | Float64 | ✅ | Yes |
| BOOLEAN | Boolean | ✅ | Yes |
| ARRAY | Array(T) | ✅ | No |
| MAP | Map(Primitive, T) | ✅ | No |
| STRUCT | Variant(T1, T2, …) | ✅ | No |
| STRUCT | Tuple(a T1, b T2, …) | ✅ | No |
| STRUCT | Nested(a T1, b T2, …) | ✅ | No |
| BYTES | String | ✅ | No |
| org.apache.kafka.connect.data.Time | Int64 / DateTime64 | ✅ | No |
| org.apache.kafka.connect.data.Timestamp | Int32 / Date32 | ✅ | No |
| org.apache.kafka.connect.data.Decimal | Decimal | ✅ | No |
スキーマ宣言なし:
レコードはJSONに変換され、ClickHouseにJSONEachRowフォーマットの値として送信されます。
設定レシピ
以下は、すぐに開始するための一般的な設定レシピです。
基本設定
開始するための最も基本的な設定です - Kafka Connect を分散モードで実行し、ClickHouse サーバーが localhost:8443 でSSLを有効にして実行されていることを前提とし、データはスキーマレスのJSONです。
{
"name": "clickhouse-connect",
"config": {
"connector.class": "com.clickhouse.kafka.connect.ClickHouseSinkConnector",
"tasks.max": "1",
"consumer.override.max.poll.records": "5000",
"consumer.override.max.partition.fetch.bytes": "5242880",
"database": "default",
"errors.retry.timeout": "60",
"exactlyOnce": "false",
"hostname": "localhost",
"port": "8443",
"ssl": "true",
"jdbcConnectionProperties": "?ssl=true&sslmode=strict",
"username": "default",
"password": "<PASSWORD>",
"topics": "<TOPIC_NAME>",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
"clickhouseSettings": ""
}
}
複数トピックでの基本設定
コネクタは複数のトピックからデータを取得できます。
{
"name": "clickhouse-connect",
"config": {
"connector.class": "com.clickhouse.kafka.connect.ClickHouseSinkConnector",
...
"topics": "SAMPLE_TOPIC, ANOTHER_TOPIC, YET_ANOTHER_TOPIC",
...
}
}
DLQを使用した基本設定
{
"name": "clickhouse-connect",
"config": {
"connector.class": "com.clickhouse.kafka.connect.ClickHouseSinkConnector",
...
"errors.tolerance": "all",
"errors.deadletterqueue.topic.name": "<DLQ_TOPIC>",
"errors.deadletterqueue.context.headers.enable": "true",
}
}
異なるデータ形式での使用
Avro スキーマサポート
{
"name": "clickhouse-connect",
"config": {
"connector.class": "com.clickhouse.kafka.connect.ClickHouseSinkConnector",
...
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "<SCHEMA_REGISTRY_HOST>:<PORT>",
"value.converter.schemas.enable": "true",
}
}
Protobuf スキーマサポート
{
"name": "clickhouse-connect",
"config": {
"connector.class": "com.clickhouse.kafka.connect.ClickHouseSinkConnector",
...
"value.converter": "io.confluent.connect.protobuf.ProtobufConverter",
"value.converter.schema.registry.url": "<SCHEMA_REGISTRY_HOST>:<PORT>",
"value.converter.schemas.enable": "true",
}
}
注意: クラスが足りないという問題に直面した場合、すべての環境においてprotobufコンバータが付属しているわけではないため、依存ファイルを含むJarの別のリリースが必要になるかもしれません。
JSON スキーマサポート
{
"name": "clickhouse-connect",
"config": {
"connector.class": "com.clickhouse.kafka.connect.ClickHouseSinkConnector",
...
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
}
}
String サポート
コネクタは異なるClickHouseフォーマットでのStringコンバータをサポートします:JSON、CSV、TSV。
{
"name": "clickhouse-connect",
"config": {
"connector.class": "com.clickhouse.kafka.connect.ClickHouseSinkConnector",
...
"value.converter": "org.apache.kafka.connect.storage.StringConverter",
"customInsertFormat": "true",
"insertFormat": "CSV"
}
}
ロギング
クライアントKafka Connect Platformによってロギングが自動的に提供されます。ロギングの送信先と形式はKafka connectの設定ファイルを通して設定できます。
Confluent Platformを使用する場合、CLIコマンドを実行してログを表示することができます:
confluent local services connect log
追加の詳細については公式のチュートリアルをご覧ください。
モニタリング
ClickHouse Kafka ConnectはJava Management Extensions (JMX)を通してランタイムメトリックをレポートします。JMXはKafka Connectorでデフォルトで有効になっています。
ClickHouse Connect MBeanName:
com.clickhouse:type=ClickHouseKafkaConnector,name=SinkTask{id}
ClickHouse Kafka Connectは次のメトリックを報告します:
| 名前 | タイプ | 説明 |
|---|---|---|
| receivedRecords | long | 受信したレコードの総数。 |
| recordProcessingTime | long | レコードを統一された構造にグループ化および変換するのに費やされた総時間(ナノ秒単位)。 |
| taskProcessingTime | long | データをClickHouseに処理および挿入するのに費やされた総時間(ナノ秒単位)。 |
制限事項
- 削除はサポートされていません。
- バッチサイズはKafka Consumerのプロパティから継承されます。
- Exactly-onceをKeeperMapで使用していてオフセットが変更または戻された場合、その特定のトピックからKeeperMapの内容を削除する必要があります。(さらなる詳細については下記のトラブルシューティングガイドをご覧ください)
パフォーマンスの調整
もし「Sinkコネクタのバッチサイズを調整したい」と考えたことがあるとしたら、このセクションはそのためのものです。
Connect Fetch対Connector Poll
Kafka Connect(我々のSinkコネクタが基づいているフレームワーク)は、バックグラウンドでKafkaトピックからメッセージを取得します(コネクタとは独立して)。
このプロセスは fetch.min.bytes および fetch.max.bytes を使用して制御できます。fetch.min.bytes はフレームワークがコネクタに値を渡す前に必要な最小量を設定し(時間制限は fetch.max.wait.ms によって設定)、fetch.max.bytes は上限サイズを設定します。もしコネクタに大きなバッチを渡したい場合は、最小取得または最大待機を増やしてより大きなデータバンドルを構築するオプションがあります。
取得されたデータは次にコネクタクライアントがメッセージをポーリングすることによって消費され、各ポーリングの量はmax.poll.records によって制御されます。注意してください、フェッチはポールとは独立しています!
これらの設定を調整する際、ユーザーはフェッチサイズが max.poll.records の複数のバッチを生成することを目指すべきです(fetch.min.bytes および fetch.max.bytes は圧縮データを表していることを念頭に置いてください) - そうすることで、各コネクタタスクが可能な限り大きなバッチを挿入しています。
ClickHouseは大小を問わず頻繁に行われる小さいバッチよりも、多少の遅延があっても大バッチに最適化されています - バッチが大きいほど良いです。
consumer.max.poll.records=5000
consumer.max.partition.fetch.bytes=5242880
詳細についてはConfluentのドキュメントまたはKafkaのドキュメントをご覧ください。
高スループットの複数トピック
もしコネクタが複数のトピックを購読するよう設定されており、topic2TableMapを使用してトピックをテーブルにマッピングしている場合でも、挿入でボトルネックが発生して消費者ラグが見られるときは、それぞれのトピックごとに1つのコネクタを作成することを検討してください。このボトルネックの主な原因は、現在バッチがテーブルに対して逐次的に挿入されているからです。
1つのコネクタをトピックごとに作成することは、可能な限り最速の挿入速度を得るための回避策です。
トラブルシューティング
"State mismatch for topic [someTopic] partition [0]"
これは、KeeperMapに保存されたオフセットがKafkaに保存されたオフセットと異なる場合に発生します。通常、トピックが削除された場合やオフセットが手動で調整された場合に発生します。 これを解決するには、その特定のトピックとパーティションに対して保存された古い値を削除する必要があります。
注意: この調整にはexactly-onceの影響があります。
"コネクタが再試行するエラーは何か?"
現在は一時的で再試行可能と考えられるエラーに焦点を当てています。以下を含みます:
ClickHouseException- これはオーバーロードされた場合などにClickHouseが投げることができる一般的な例外です。 特に一時的と考えられるエラーコード:- 3 - UNEXPECTED_END_OF_FILE
- 159 - TIMEOUT_EXCEEDED
- 164 - READONLY
- 202 - TOO_MANY_SIMULTANEOUS_QUERIES
- 203 - NO_FREE_CONNECTION
- 209 - SOCKET_TIMEOUT
- 210 - NETWORK_ERROR
- 242 - TABLE_IS_READ_ONLY
- 252 - TOO_MANY_PARTS
- 285 - TOO_FEW_LIVE_REPLICAS
- 319 - UNKNOWN_STATUS_OF_INSERT
- 425 - SYSTEM_ERROR
- 999 - KEEPER_EXCEPTION
- 1002 - UNKNOWN_EXCEPTION
SocketTimeoutException- ソケットがタイムアウトした場合にスローされます。UnknownHostException- ホストが解決できない場合にスローされます。IOException- ネットワークに問題がある場合にスローされます。
"全てのデータが空白/ゼロである"
データのフィールドがテーブルのフィールドと一致していない可能性が高いです - これは特にCDC(およびDebeziumフォーマット)で一般的です。 一般的な解決策は、コネクタ設定にflatten変換を追加することです:
transforms=flatten
transforms.flatten.type=org.apache.kafka.connect.transforms.Flatten$Value
transforms.flatten.delimiter=_
これによりデータがネストされたJSONからフラットなJSONに変換され(デリミタとして _ を使用)、テーブル内のフィールドは「field1_field2_field3」の形式で構成されます(例: "before_id", "after_id" など)。
"KafkaキーをClickHouseで使用したい"
Kafkaキーはデフォルトで値フィールドに保存されませんが、KeyToValue 変換を使用してキーを値フィールドに移動することができます(新しい _key フィールド名の下):
transforms=keyToValue
transforms.keyToValue.type=com.clickhouse.kafka.connect.transforms.KeyToValue
transforms.keyToValue.field=_key